
Break-It-Fix-It: Unsupervised Learning for Program Repair
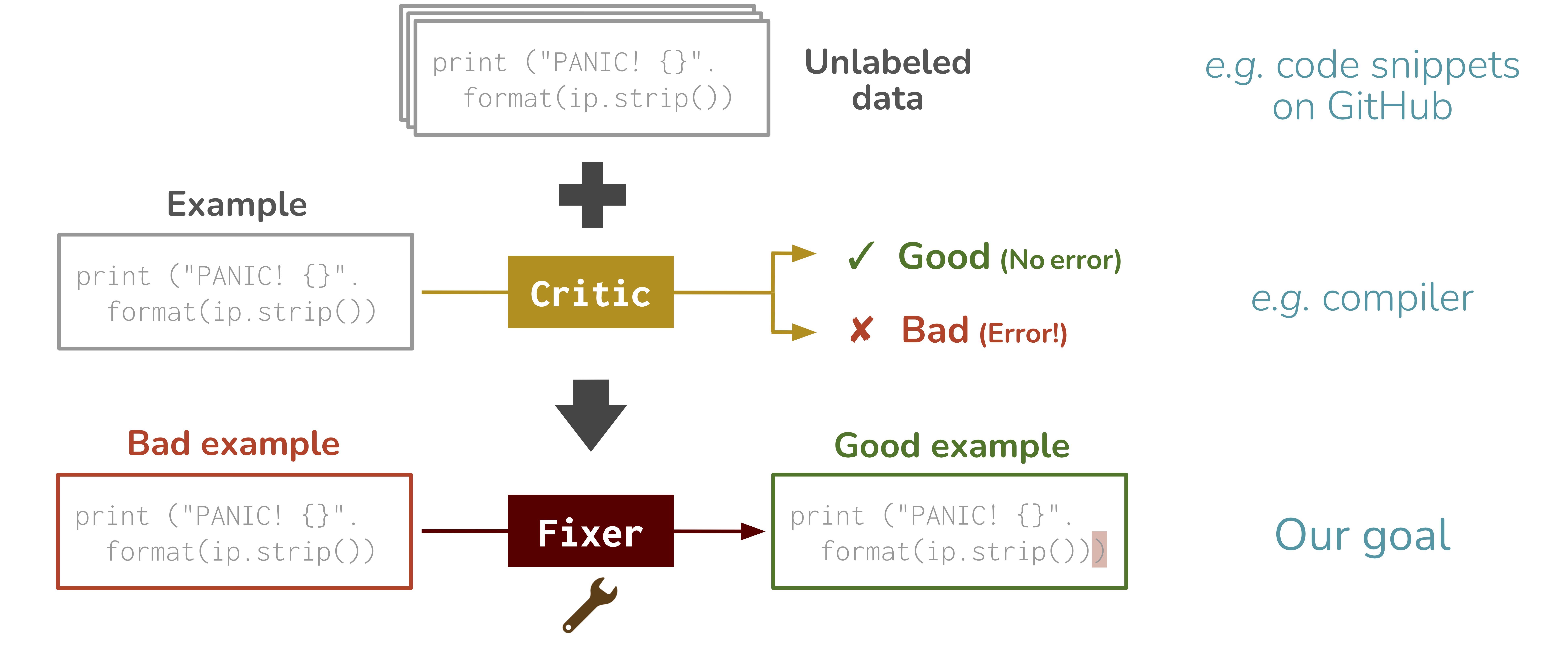
We consider repair tasks: given a critic (e.g., compiler) that assesses the quality of an input, the goal is to train a fixer that converts a bad example (e.g., code with syntax errors) into a good one (e.g., code with no syntax errors). Existing works create training data consisting of (bad, good) pairs by corrupting good examples using heuristics (e.g., dropping tokens). However, fixers trained on this synthetically-generated data do not extrapolate well to the real distribution of bad inputs. To bridge this gap, we propose a new training approach, Break-It-Fix-It (BIFI), which has two key ideas: (i) we use the critic to check a fixer's output on real bad inputs and add good (fixed) outputs to the training data, and (ii) we train a breaker to generate realistic bad code from good code. Based on these ideas, we iteratively update the breaker and the fixer while using them in conjunction to generate more paired data. We evaluate BIFI on two code repair datasets: GitHub-Python, a new dataset we introduce where the goal is to repair Python code with AST parse errors; and DeepFix, where the goal is to repair C code with compiler errors. BIFI outperforms existing methods, obtaining 90.5% repair accuracy on GitHub-Python (+28.5%) and 71.7% on DeepFix (+5.6%). Notably, BIFI does not require any labeled data; we hope it will be a strong starting point for unsupervised learning of various repair tasks.
PDF Abstract






