RealignDiff: Boosting Text-to-Image Diffusion Model with Coarse-to-fine Semantic Re-alignment
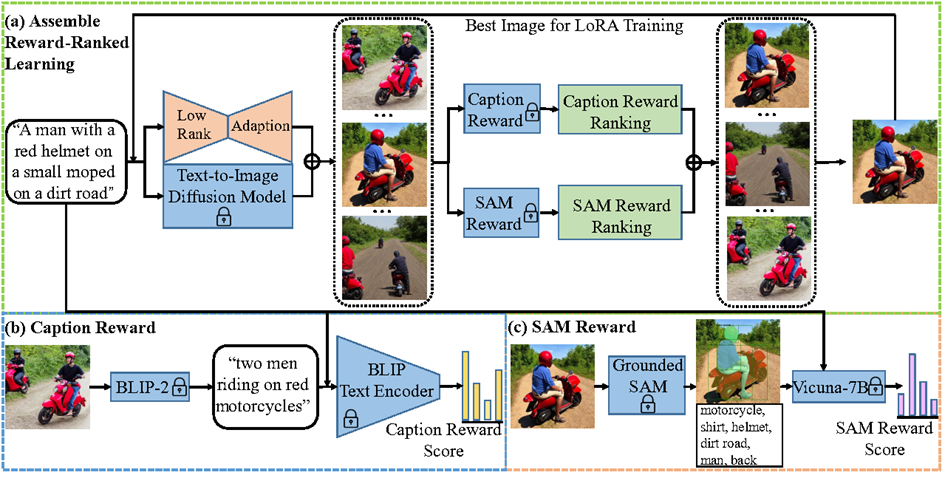
Recent advances in text-to-image diffusion models have achieved remarkable success in generating high-quality, realistic images from textual descriptions. However, these approaches have faced challenges in precisely aligning the generated visual content with the textual concepts described in the prompts. In this paper, we propose a two-stage coarse-to-fine semantic re-alignment method, named RealignDiff, aimed at improving the alignment between text and images in text-to-image diffusion models. In the coarse semantic re-alignment phase, a novel caption reward, leveraging the BLIP-2 model, is proposed to evaluate the semantic discrepancy between the generated image caption and the given text prompt. Subsequently, the fine semantic re-alignment stage employs a local dense caption generation module and a re-weighting attention modulation module to refine the previously generated images from a local semantic view. Experimental results on the MS-COCO benchmark demonstrate that the proposed two-stage coarse-to-fine semantic re-alignment method outperforms other baseline re-alignment techniques by a substantial margin in both visual quality and semantic similarity with the input prompt.
PDF Abstract



 MS COCO
MS COCO
