BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
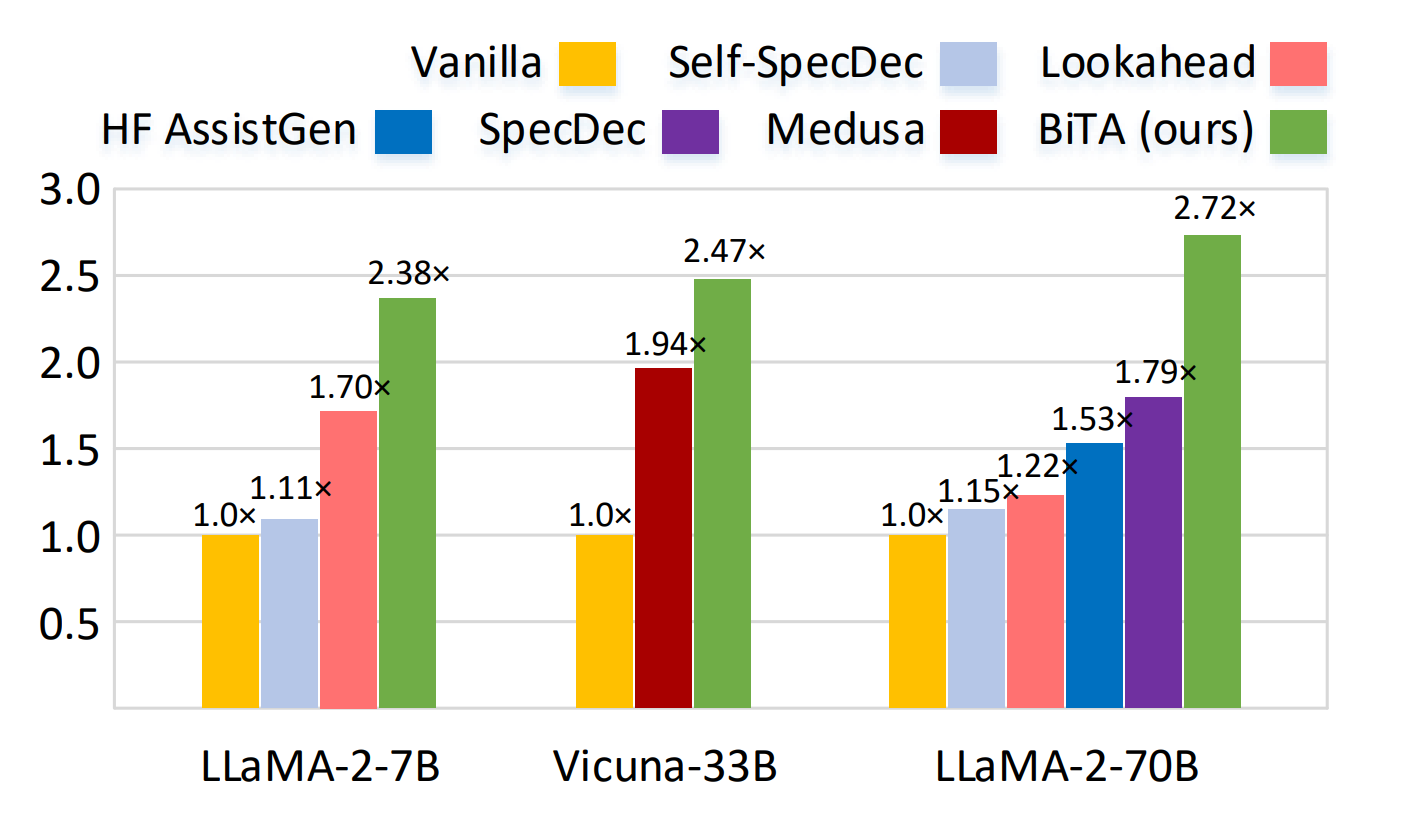
Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.
PDF Abstract
