Beyond Uniform Sampling: Offline Reinforcement Learning with Imbalanced Datasets
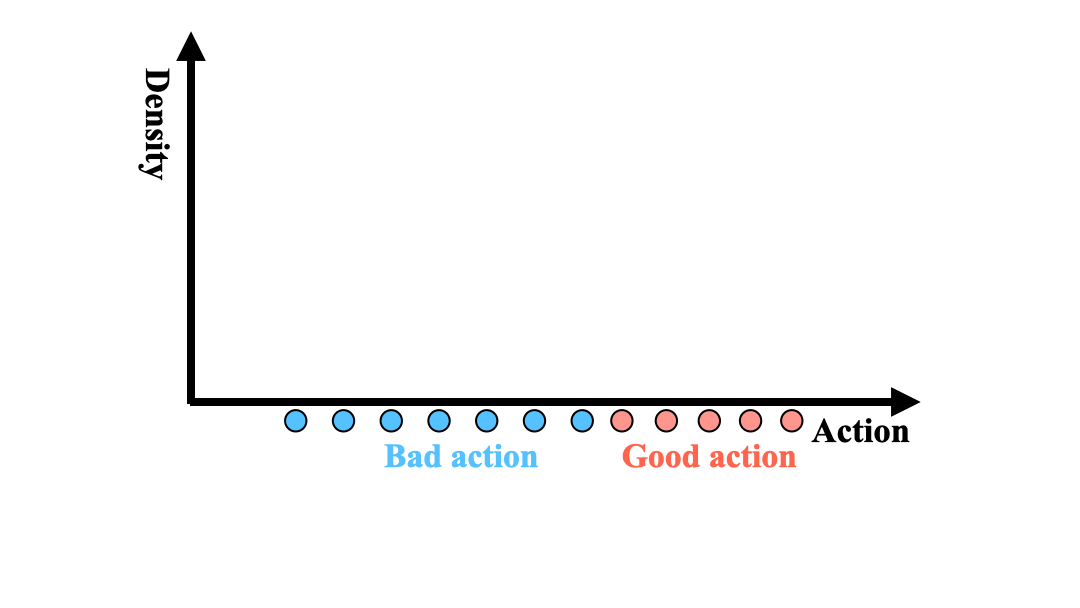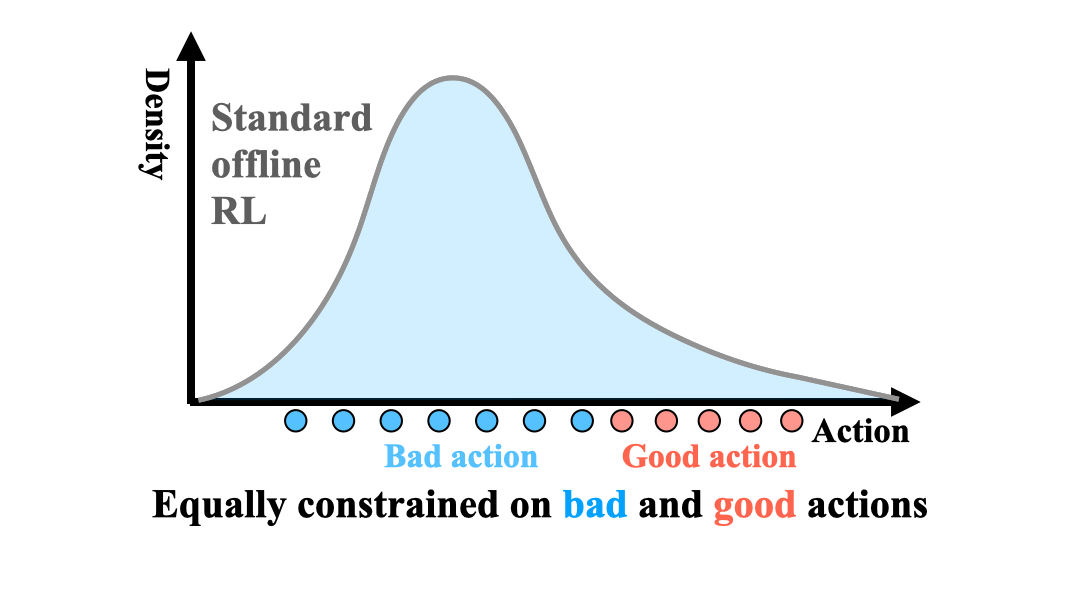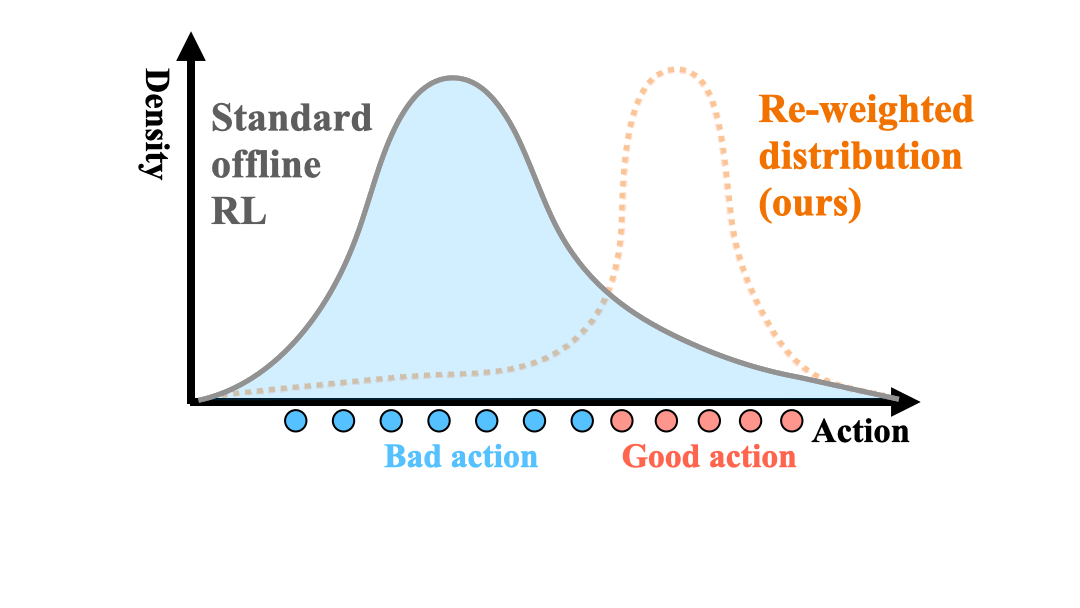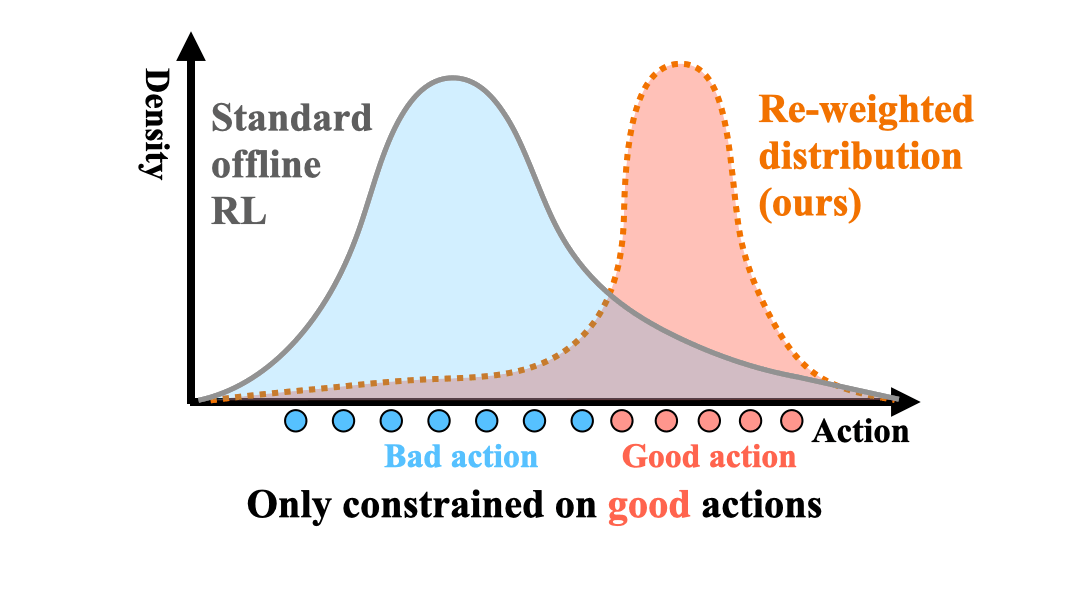
Offline policy learning is aimed at learning decision-making policies using existing datasets of trajectories without collecting additional data. The primary motivation for using reinforcement learning (RL) instead of supervised learning techniques such as behavior cloning is to find a policy that achieves a higher average return than the trajectories constituting the dataset. However, we empirically find that when a dataset is dominated by suboptimal trajectories, state-of-the-art offline RL algorithms do not substantially improve over the average return of trajectories in the dataset. We argue this is due to an assumption made by current offline RL algorithms of staying close to the trajectories in the dataset. If the dataset primarily consists of sub-optimal trajectories, this assumption forces the policy to mimic the suboptimal actions. We overcome this issue by proposing a sampling strategy that enables the policy to only be constrained to ``good data" rather than all actions in the dataset (i.e., uniform sampling). We present a realization of the sampling strategy and an algorithm that can be used as a plug-and-play module in standard offline RL algorithms. Our evaluation demonstrates significant performance gains in 72 imbalanced datasets, D4RL dataset, and across three different offline RL algorithms. Code is available at https://github.com/Improbable-AI/dw-offline-rl.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract

 D4RL
D4RL
