Beyond Hallucinations: Enhancing LVLMs through Hallucination-Aware Direct Preference Optimization
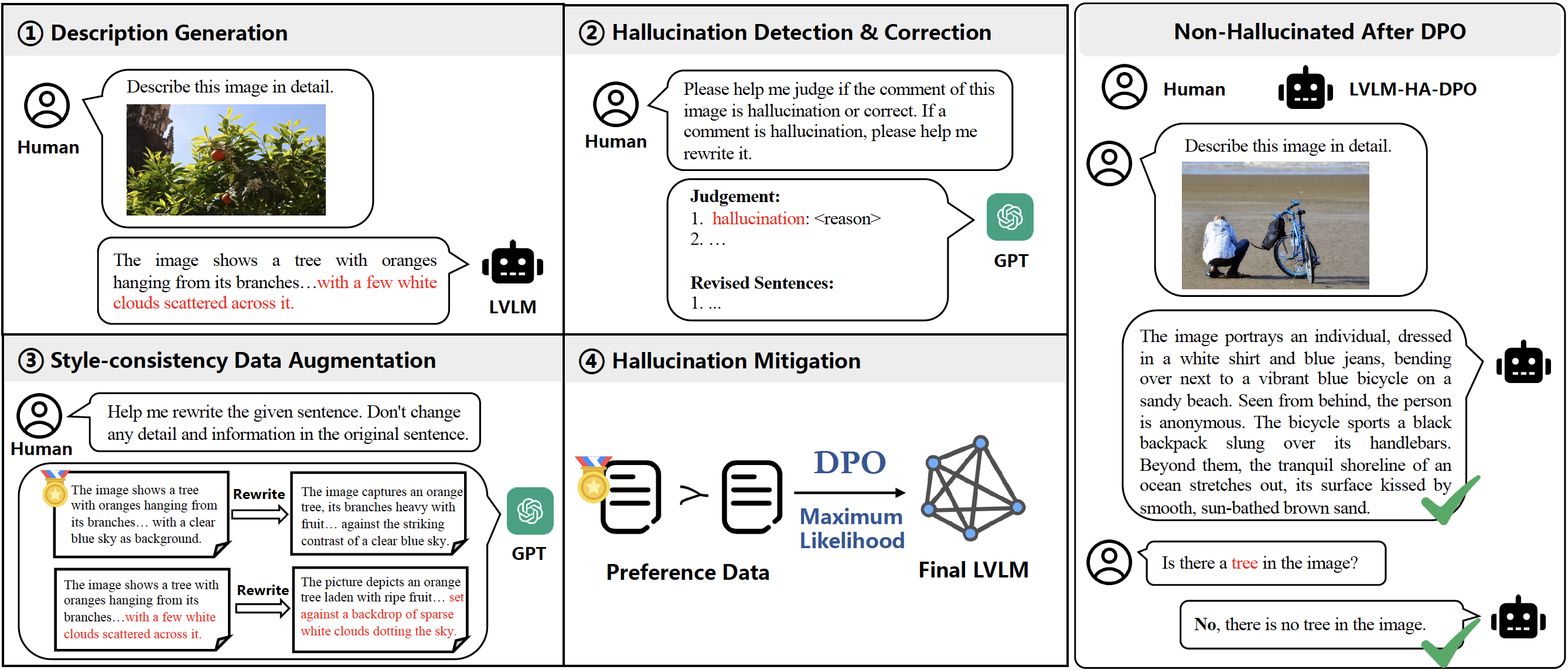
Multimodal large language models have made significant advancements in recent years, yet they still suffer from a common issue known as the "hallucination problem", in which the models generate textual descriptions that inaccurately depict or entirely fabricate content from associated images. This paper introduces a novel solution, Hallucination-Aware Direct Preference Optimization (HA-DPO), which reframes the hallucination problem as a preference selection task. The model is trained to favor the non-hallucinating response when presented with two responses of the same image (one accurate and one hallucinatory). Furthermore, this paper proposes an efficient pipeline for constructing positive~(non-hallucinatory) and negative~(hallucinatory) sample pairs, ensuring a high-quality, style-consistent dataset for robust preference learning. When applied to three mainstream multimodal models, HA-DPO significantly reduced hallucination issues and amplified the models' generalization capabilities. Notably, the MiniGPT-4 model, when enhanced with HA-DPO, demonstrated a substantial improvement: POPE accuracy rose from 51.13% to 86.13% (an absolute improvement of 35%), and the MME score surged from 932.00 to 1326.46 (a relative improvement of 42.32%). The codes, models, and datasets are made accessible at https://opendatalab.github.io/HA-DPO.
PDF Abstract

 Visual Genome
Visual Genome
