Benchmarking Large Multimodal Models against Common Corruptions
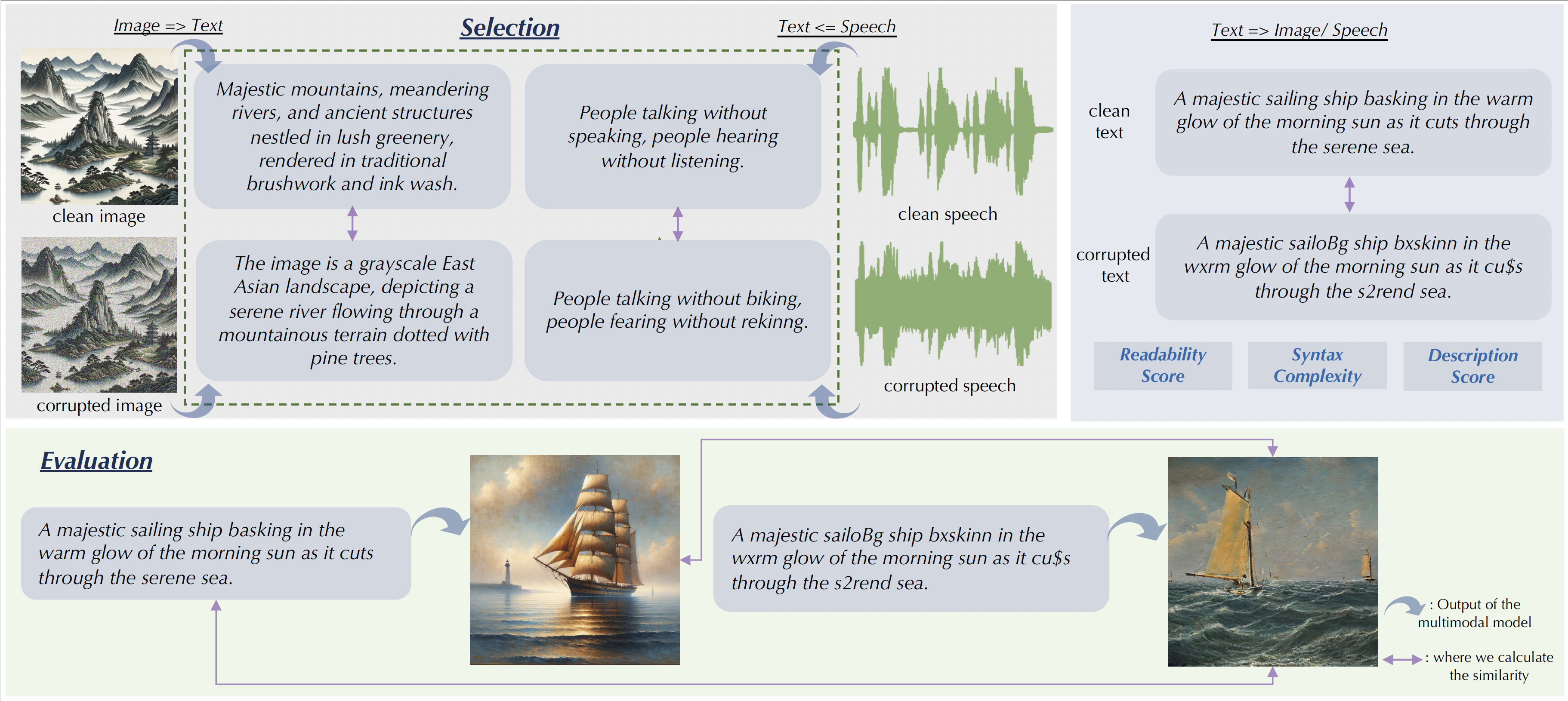
This technical report aims to fill a deficiency in the assessment of large multimodal models (LMMs) by specifically examining the self-consistency of their outputs when subjected to common corruptions. We investigate the cross-modal interactions between text, image, and speech, encompassing four essential generation tasks: text-to-image, image-to-text, text-to-speech, and speech-to-text. We create a comprehensive benchmark, named MMCBench, that covers more than 100 popular LMMs (totally over 150 model checkpoints). A thorough evaluation under common corruptions is critical for practical deployment and facilitates a better understanding of the reliability of cutting-edge LMMs. The benchmarking code is available at https://github.com/sail-sg/MMCBench
PDF Abstract

 ImageNet-C
ImageNet-C
