Benchmarking Chinese Commonsense Reasoning of LLMs: From Chinese-Specifics to Reasoning-Memorization Correlations
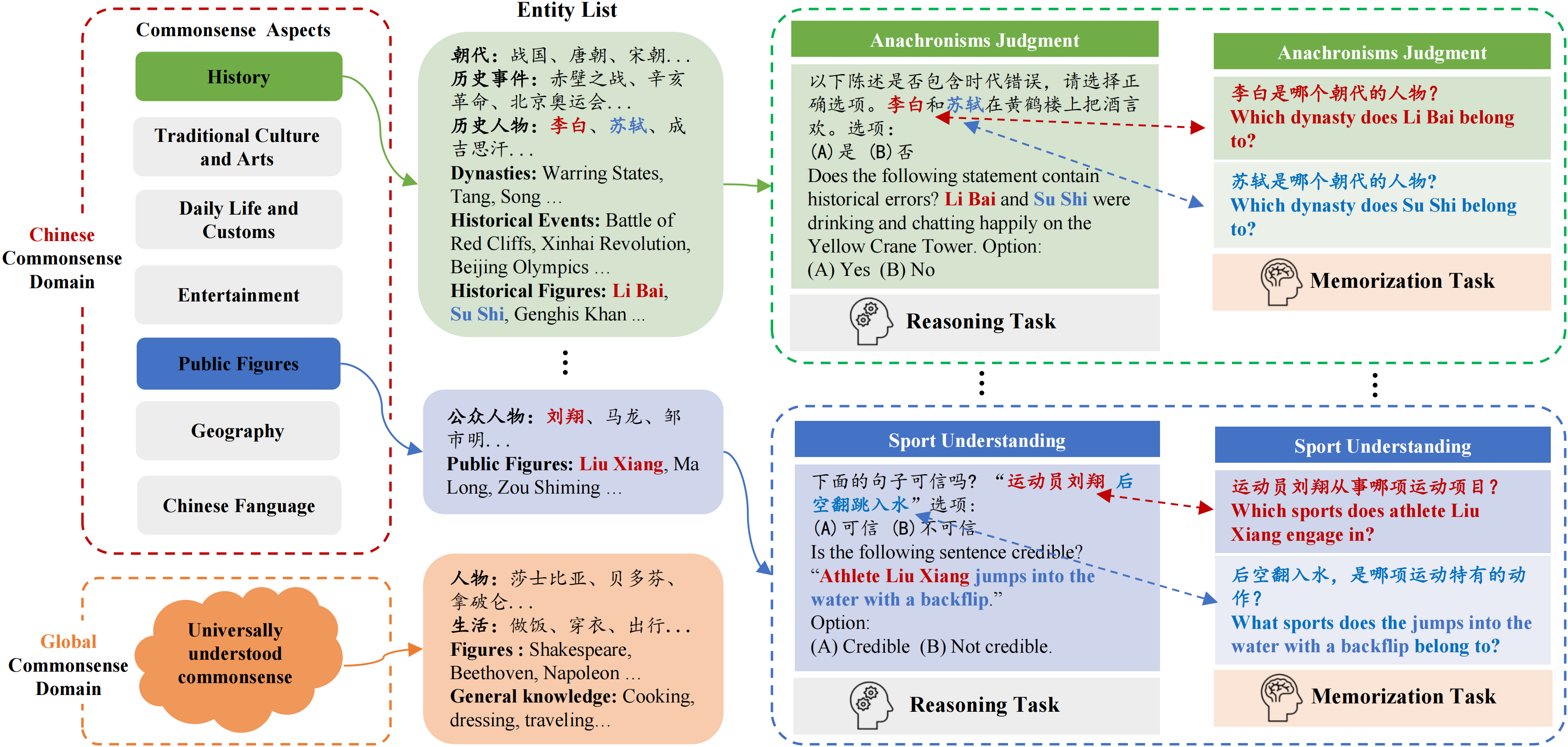
We introduce CHARM, the first benchmark for comprehensively and in-depth evaluating the commonsense reasoning ability of large language models (LLMs) in Chinese, which covers both globally known and Chinese-specific commonsense. We evaluated 7 English and 12 Chinese-oriented LLMs on CHARM, employing 5 representative prompt strategies for improving LLMs' reasoning ability, such as Chain-of-Thought. Our findings indicate that the LLM's language orientation and the task's domain influence the effectiveness of the prompt strategy, which enriches previous research findings. We built closely-interconnected reasoning and memorization tasks, and found that some LLMs struggle with memorizing Chinese commonsense, affecting their reasoning ability, while others show differences in reasoning despite similar memorization performance. We also evaluated the LLMs' memorization-independent reasoning abilities and analyzed the typical errors. Our study precisely identified the LLMs' strengths and weaknesses, providing the clear direction for optimization. It can also serve as a reference for studies in other fields. We will release CHARM at https://github.com/opendatalab/CHARM .
PDF Abstract
 LogiQA
LogiQA
