Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation
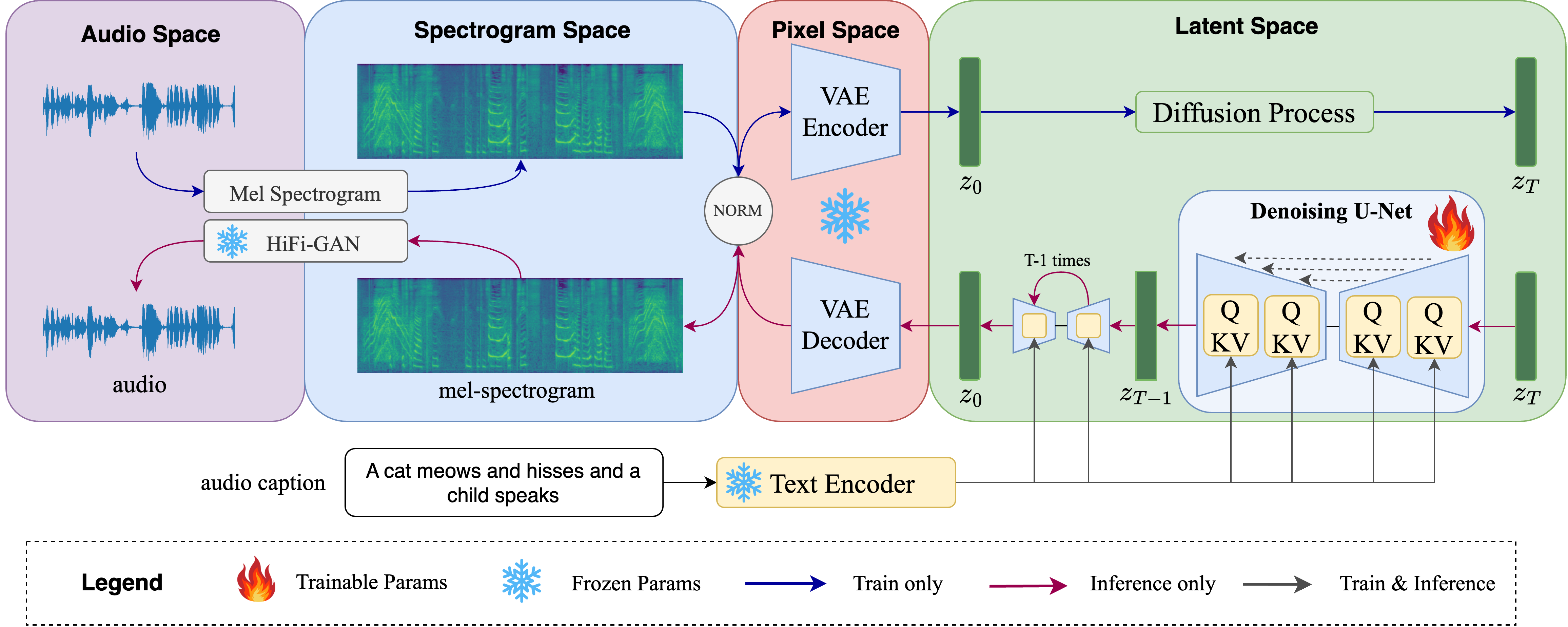
Recent advancements in diffusion models and large language models (LLMs) have significantly propelled the field of AIGC. Text-to-Audio (TTA), a burgeoning AIGC application designed to generate audio from natural language prompts, is attracting increasing attention. However, existing TTA studies often struggle with generation quality and text-audio alignment, especially for complex textual inputs. Drawing inspiration from state-of-the-art Text-to-Image (T2I) diffusion models, we introduce Auffusion, a TTA system adapting T2I model frameworks to TTA task, by effectively leveraging their inherent generative strengths and precise cross-modal alignment. Our objective and subjective evaluations demonstrate that Auffusion surpasses previous TTA approaches using limited data and computational resource. Furthermore, previous studies in T2I recognizes the significant impact of encoder choice on cross-modal alignment, like fine-grained details and object bindings, while similar evaluation is lacking in prior TTA works. Through comprehensive ablation studies and innovative cross-attention map visualizations, we provide insightful assessments of text-audio alignment in TTA. Our findings reveal Auffusion's superior capability in generating audios that accurately match textual descriptions, which further demonstrated in several related tasks, such as audio style transfer, inpainting and other manipulations. Our implementation and demos are available at https://auffusion.github.io.
PDF Abstract Colab
Colab



 AudioCaps
AudioCaps
 Clotho
Clotho

