Audio-Visual Speech Separation in Noisy Environments with a Lightweight Iterative Model
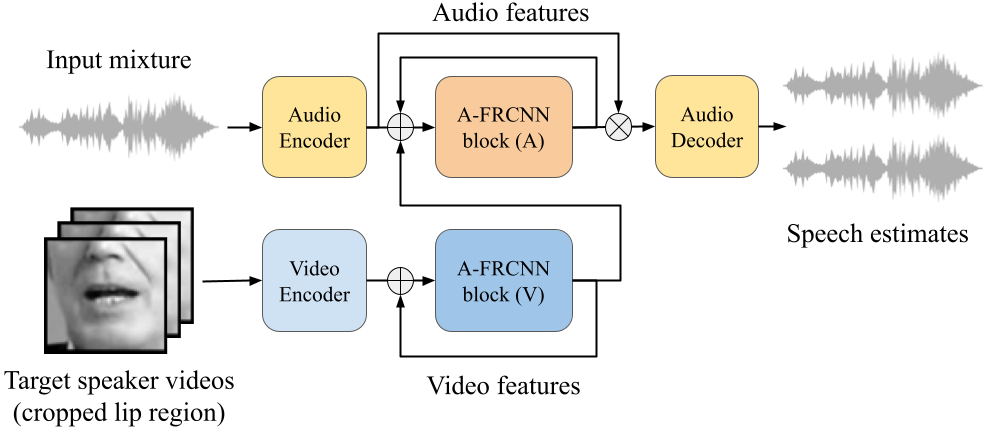
We propose Audio-Visual Lightweight ITerative model (AVLIT), an effective and lightweight neural network that uses Progressive Learning (PL) to perform audio-visual speech separation in noisy environments. To this end, we adopt the Asynchronous Fully Recurrent Convolutional Neural Network (A-FRCNN), which has shown successful results in audio-only speech separation. Our architecture consists of an audio branch and a video branch, with iterative A-FRCNN blocks sharing weights for each modality. We evaluated our model in a controlled environment using the NTCD-TIMIT dataset and in-the-wild using a synthetic dataset that combines LRS3 and WHAM!. The experiments demonstrate the superiority of our model in both settings with respect to various audio-only and audio-visual baselines. Furthermore, the reduced footprint of our model makes it suitable for low resource applications.
PDF Abstract

