AsymFormer: Asymmetrical Cross-Modal Representation Learning for Mobile Platform Real-Time RGB-D Semantic Segmentation
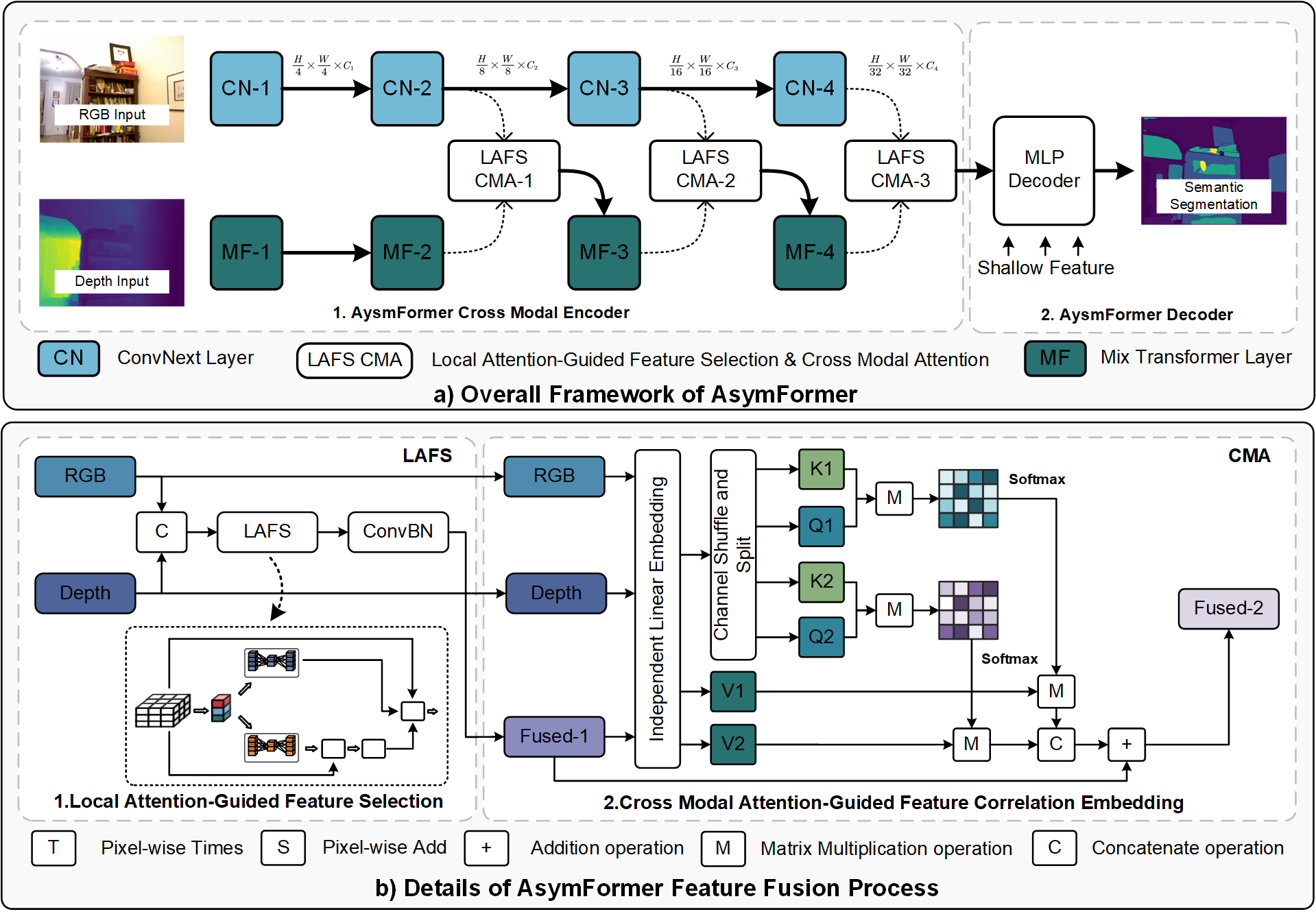
Understanding indoor scenes is crucial for urban studies. Considering the dynamic nature of indoor environments, effective semantic segmentation requires both real-time operation and high accuracy.To address this, we propose AsymFormer, a novel network that improves real-time semantic segmentation accuracy using RGB-D multi-modal information without substantially increasing network complexity. AsymFormer uses an asymmetrical backbone for multimodal feature extraction, reducing redundant parameters by optimizing computational resource distribution. To fuse asymmetric multimodal features, a Local Attention-Guided Feature Selection (LAFS) module is used to selectively fuse features from different modalities by leveraging their dependencies. Subsequently, a Cross-Modal Attention-Guided Feature Correlation Embedding (CMA) module is introduced to further extract cross-modal representations. The AsymFormer demonstrates competitive results with 54.1% mIoU on NYUv2 and 49.1% mIoU on SUNRGBD. Notably, AsymFormer achieves an inference speed of 65 FPS (79 FPS after implementing mixed precision quantization) on RTX3090, demonstrating that AsymFormer can strike a balance between high accuracy and efficiency.
PDF Abstract




 ImageNet
ImageNet
 NYUv2
NYUv2
 SUN RGB-D
SUN RGB-D

