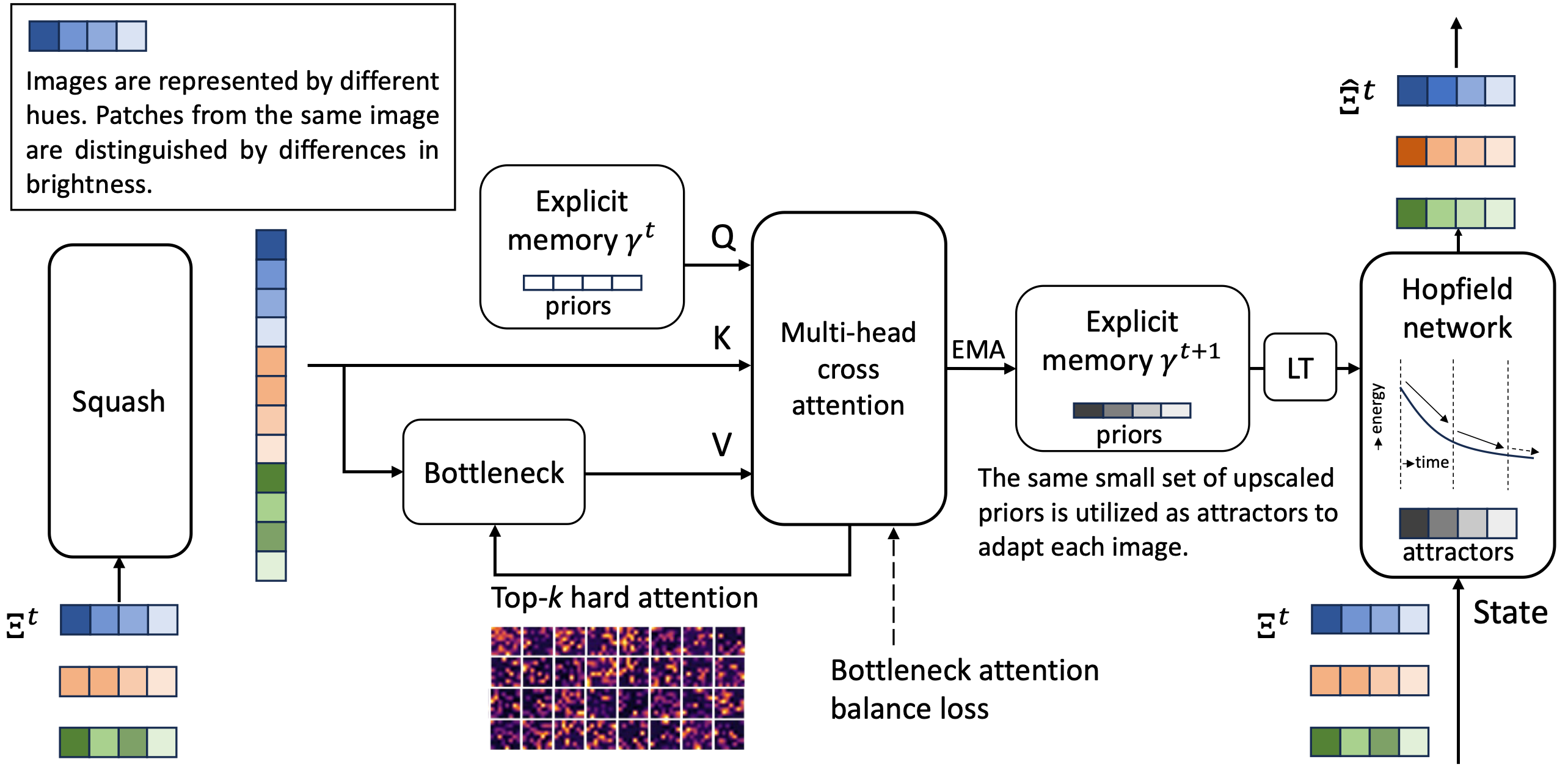
Associative Transformer
Emerging from the pairwise attention in conventional Transformers, there is a growing interest in sparse attention mechanisms that align more closely with localized, contextual learning in the biological brain. Existing studies such as the Coordination method employ iterative cross-attention mechanisms with a bottleneck to enable the sparse association of inputs. However, these methods are parameter inefficient and fail in more complex relational reasoning tasks. To this end, we propose Associative Transformer (AiT) to enhance the association among sparsely attended input patches, improving parameter efficiency and performance in relational reasoning tasks. AiT leverages a learnable explicit memory, comprised of various specialized priors, with a bottleneck attention to facilitate the extraction of diverse localized features. Moreover, we propose a novel associative memory-enabled patch reconstruction with a Hopfield energy function. The extensive experiments in four image classification tasks with three different sizes of AiT demonstrate that AiT requires significantly fewer parameters and attention layers while outperforming Vision Transformers and a broad range of sparse Transformers. Additionally, AiT establishes new SOTA performance in the Sort-of-CLEVR dataset, outperforming the previous Coordination method.
PDF Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 CLEVR
CLEVR
 Oxford-IIIT Pet Dataset
Oxford-IIIT Pet Dataset
