Assessing Logical Puzzle Solving in Large Language Models: Insights from a Minesweeper Case Study
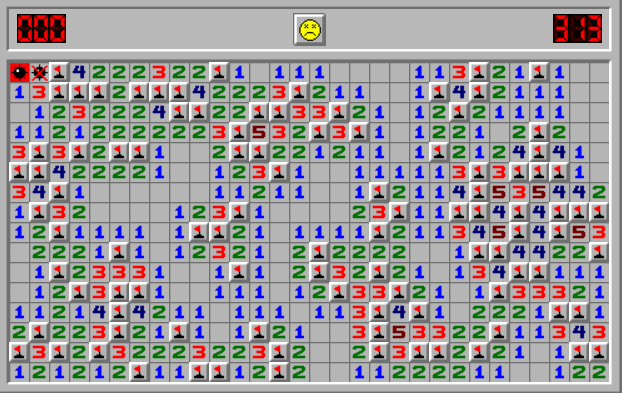
Large Language Models (LLMs) have shown remarkable proficiency in language understanding and have been successfully applied to a variety of real-world tasks through task-specific fine-tuning or prompt engineering. Despite these advancements, it remains an open question whether LLMs are fundamentally capable of reasoning and planning, or if they primarily rely on recalling and synthesizing information from their training data. In our research, we introduce a novel task -- Minesweeper -- specifically designed in a format unfamiliar to LLMs and absent from their training datasets. This task challenges LLMs to identify the locations of mines based on numerical clues provided by adjacent opened cells. Successfully completing this task requires an understanding of each cell's state, discerning spatial relationships between the clues and mines, and strategizing actions based on logical deductions drawn from the arrangement of the cells. Our experiments, including trials with the advanced GPT-4 model, indicate that while LLMs possess the foundational abilities required for this task, they struggle to integrate these into a coherent, multi-step logical reasoning process needed to solve Minesweeper. These findings highlight the need for further research to understand the nature of reasoning capabilities in LLMs under similar circumstances, and to explore pathways towards more sophisticated AI reasoning and planning models.
PDF Abstract

