apricot: Submodular selection for data summarization in Python
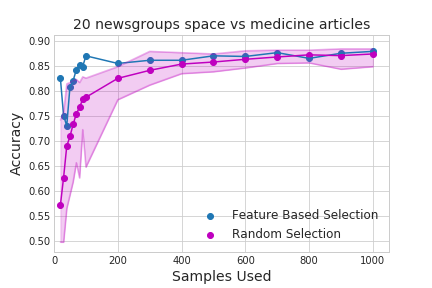
We present apricot, an open source Python package for selecting representative subsets from large data sets using submodular optimization. The package implements an efficient greedy selection algorithm that offers strong theoretical guarantees on the quality of the selected set. Two submodular set functions are implemented in apricot: facility location, which is broadly applicable but requires memory quadratic in the number of examples in the data set, and a feature-based function that is less broadly applicable but can scale to millions of examples. Apricot is extremely efficient, using both algorithmic speedups such as the lazy greedy algorithm and code optimizers such as numba. We demonstrate the use of subset selection by training machine learning models to comparable accuracy using either the full data set or a representative subset thereof. This paper presents an explanation of submodular selection, an overview of the features in apricot, and an application to several data sets. The code and tutorial Jupyter notebooks are available at https://github.com/jmschrei/apricot
PDF Abstract
 MNIST
MNIST
