ANLS* -- A Universal Document Processing Metric for Generative Large Language Models
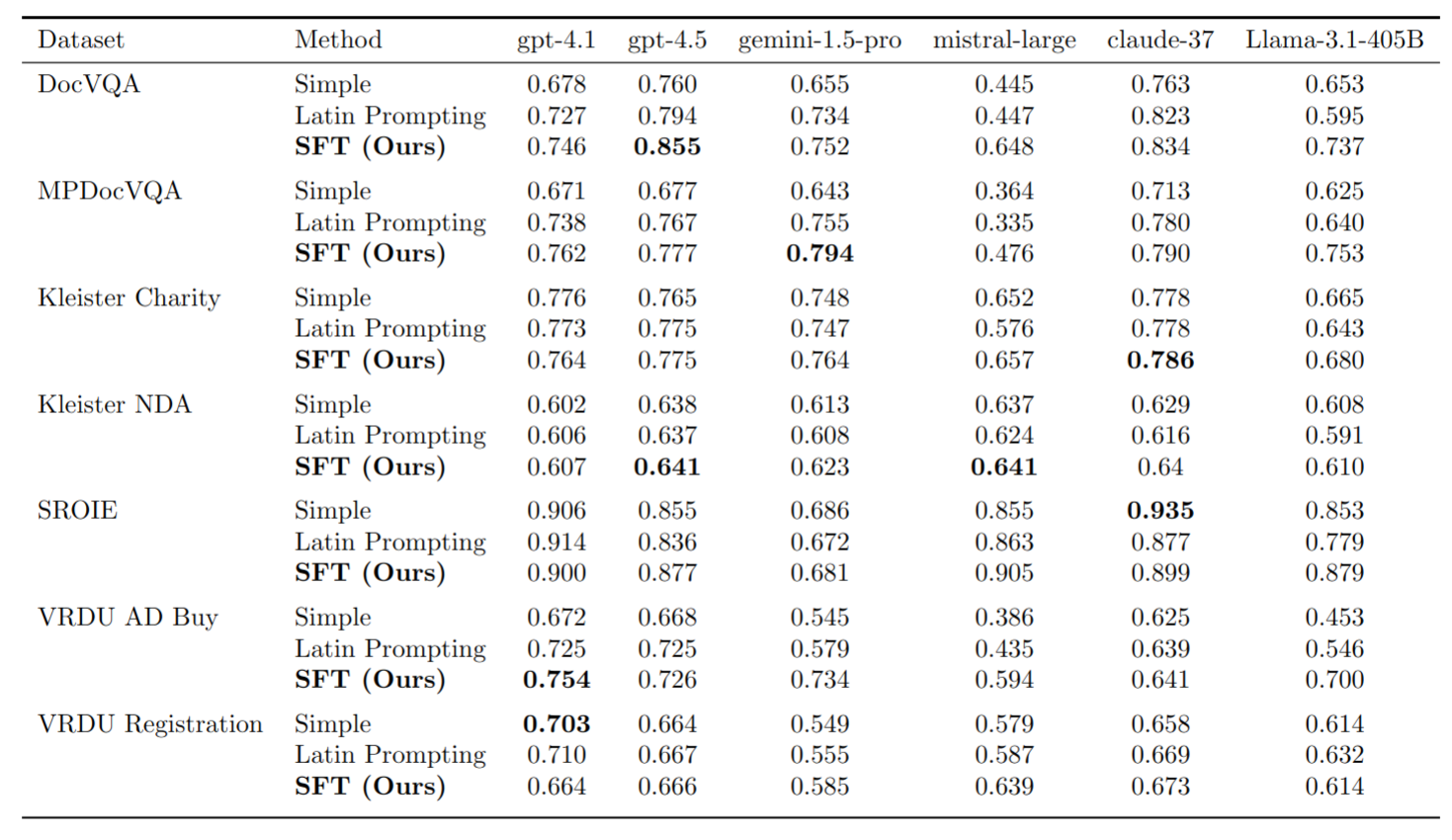
Traditionally, discriminative models have been the predominant choice for tasks like document classification and information extraction. These models make predictions that fall into a limited number of predefined classes, facilitating a binary true or false evaluation and enabling the direct calculation of metrics such as the F1 score. However, recent advancements in generative large language models (GLLMs) have prompted a shift in the field due to their enhanced zero-shot capabilities, which eliminate the need for a downstream dataset and computationally expensive fine-tuning. However, evaluating GLLMs presents a challenge as the binary true or false evaluation used for discriminative models is not applicable to the predictions made by GLLMs. This paper introduces a new metric for generative models called ANLS* for evaluating a wide variety of tasks, including information extraction and classification tasks. The ANLS* metric extends existing ANLS metrics as a drop-in-replacement and is still compatible with previously reported ANLS scores. An evaluation of 7 different datasets, 6 different GLLMs and 3 different prompting methods using the ANLS* metric is also provided, demonstrating the importance of the proposed metric. We also benchmark a novel approach to generate prompts for documents, called SFT, against other prompting techniques such as LATIN. In 27 out of 35 cases, SFT outperforms other techniques and improves the state-of-the-art, sometimes by as much as $18$ percentage points. Sources are available at https://github.com/deepopinion/anls_star_metric
PDF Abstract
 SROIE
SROIE
