Alleviating Matthew Effect of Offline Reinforcement Learning in Interactive Recommendation
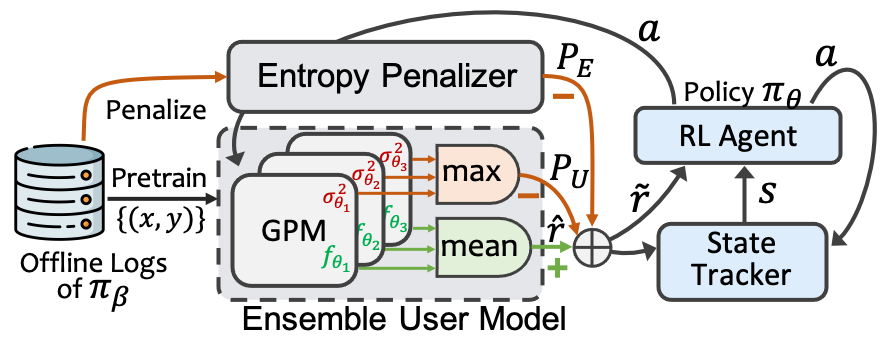
Offline reinforcement learning (RL), a technology that offline learns a policy from logged data without the need to interact with online environments, has become a favorable choice in decision-making processes like interactive recommendation. Offline RL faces the value overestimation problem. To address it, existing methods employ conservatism, e.g., by constraining the learned policy to be close to behavior policies or punishing the rarely visited state-action pairs. However, when applying such offline RL to recommendation, it will cause a severe Matthew effect, i.e., the rich get richer and the poor get poorer, by promoting popular items or categories while suppressing the less popular ones. It is a notorious issue that needs to be addressed in practical recommender systems. In this paper, we aim to alleviate the Matthew effect in offline RL-based recommendation. Through theoretical analyses, we find that the conservatism of existing methods fails in pursuing users' long-term satisfaction. It inspires us to add a penalty term to relax the pessimism on states with high entropy of the logging policy and indirectly penalizes actions leading to less diverse states. This leads to the main technical contribution of the work: Debiased model-based Offline RL (DORL) method. Experiments show that DORL not only captures user interests well but also alleviates the Matthew effect. The implementation is available via https://github.com/chongminggao/DORL-codes.
PDF Abstract


 KuaiRec
KuaiRec
