Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators
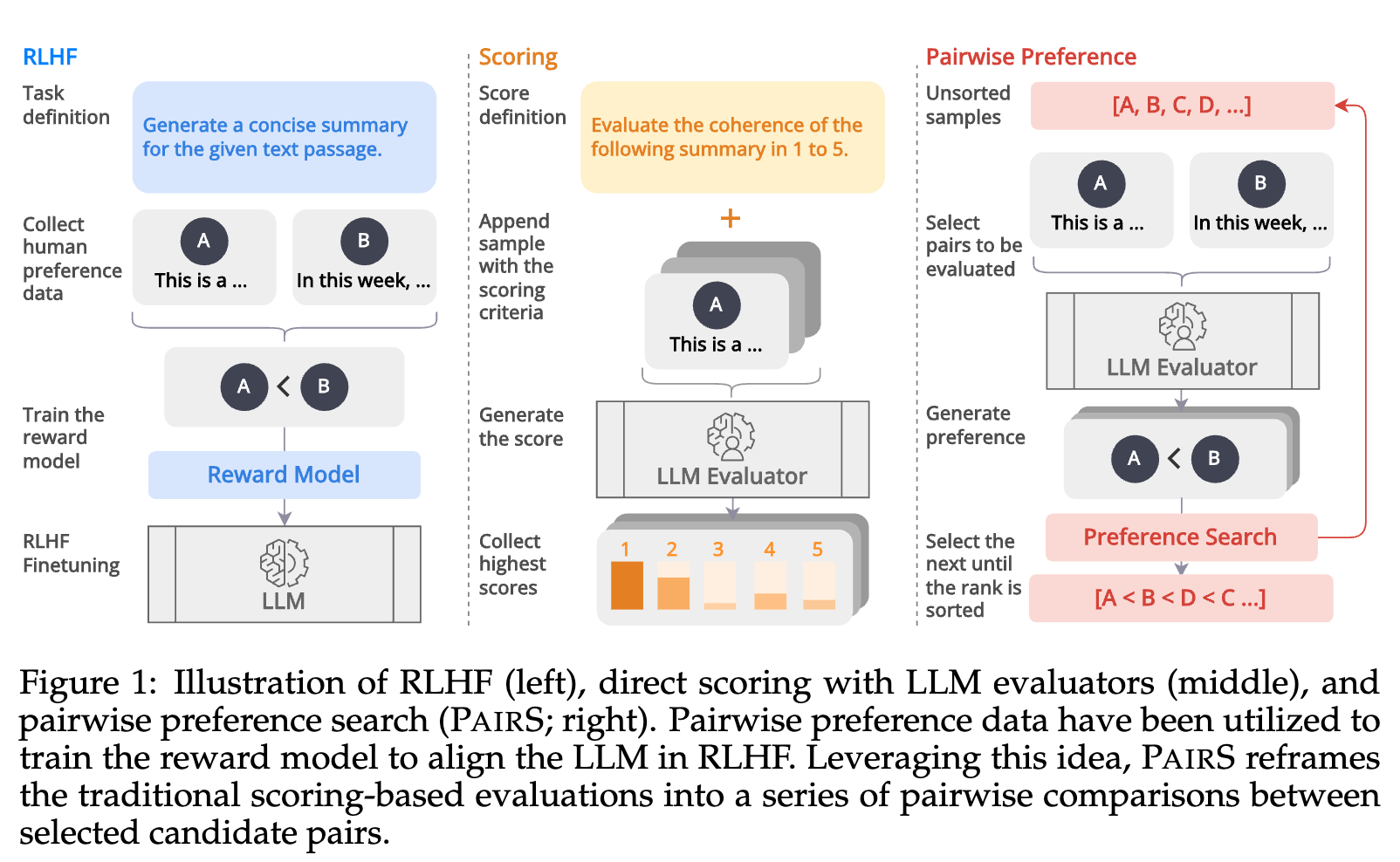
Large Language Models (LLMs) have demonstrated promising capabilities as automatic evaluators in assessing the quality of generated natural language. However, LLMs still exhibit biases in evaluation and often struggle to generate coherent evaluations that align with human assessments. In this work, we first conduct a systematic study of the misalignment between LLM evaluators and human judgement, revealing that existing calibration methods aimed at mitigating biases are insufficient for effectively aligning LLM evaluators. Inspired by the use of preference data in RLHF, we formulate the evaluation as a ranking problem and introduce Pairwise-preference Search (PairS), an uncertainty-guided search method that employs LLMs to conduct pairwise comparisons and efficiently ranks candidate texts. PairS achieves state-of-the-art performance on representative evaluation tasks and demonstrates significant improvements over direct scoring. Furthermore, we provide insights into the role of pairwise preference in quantifying the transitivity of LLMs and demonstrate how PairS benefits from calibration.
PDF Abstract


