AGAIN-VC: A One-shot Voice Conversion using Activation Guidance and Adaptive Instance Normalization
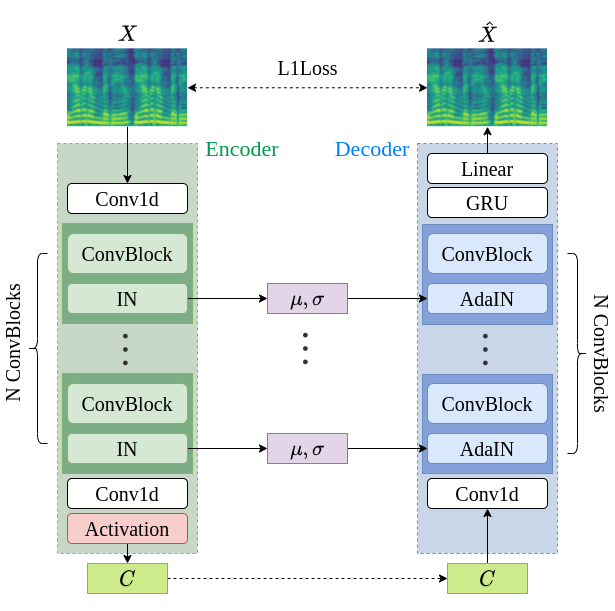
Recently, voice conversion (VC) has been widely studied. Many VC systems use disentangle-based learning techniques to separate the speaker and the linguistic content information from a speech signal. Subsequently, they convert the voice by changing the speaker information to that of the target speaker. To prevent the speaker information from leaking into the content embeddings, previous works either reduce the dimension or quantize the content embedding as a strong information bottleneck. These mechanisms somehow hurt the synthesis quality. In this work, we propose AGAIN-VC, an innovative VC system using Activation Guidance and Adaptive Instance Normalization. AGAIN-VC is an auto-encoder-based model, comprising of a single encoder and a decoder. With a proper activation as an information bottleneck on content embeddings, the trade-off between the synthesis quality and the speaker similarity of the converted speech is improved drastically. This one-shot VC system obtains the best performance regardless of the subjective or objective evaluations.
PDF Abstract Colab
Colab

