Adversarial attacks and defenses in explainable artificial intelligence: A survey
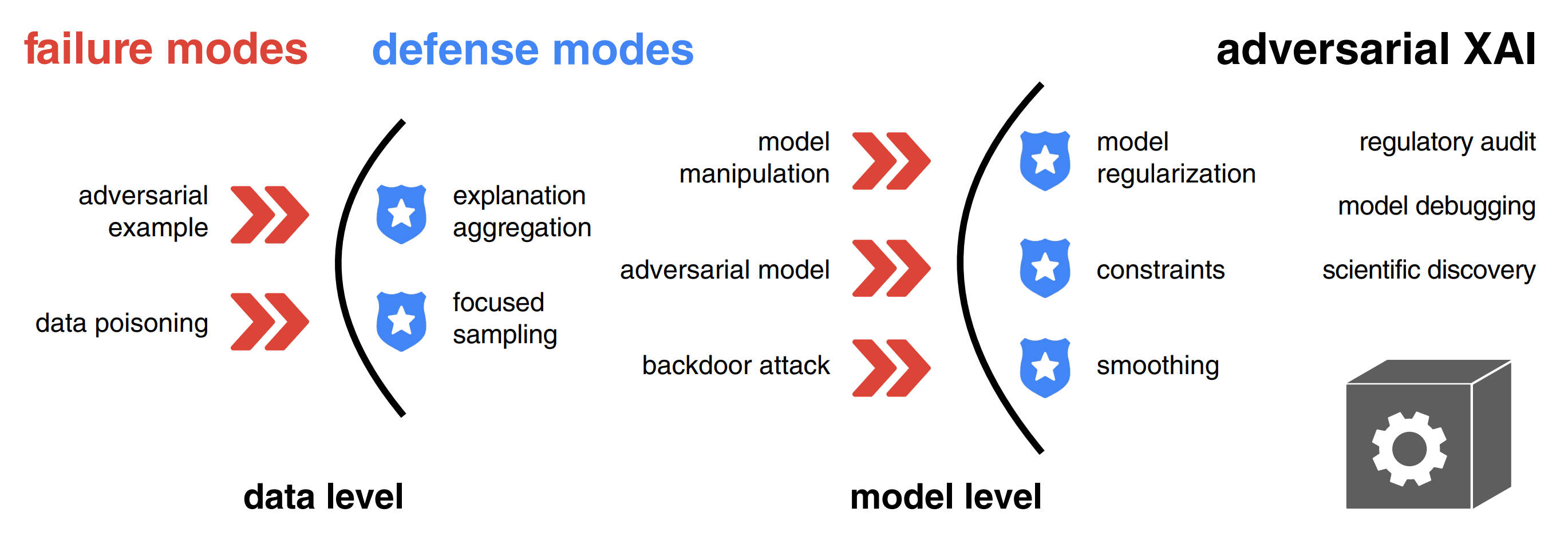
Explainable artificial intelligence (XAI) methods are portrayed as a remedy for debugging and trusting statistical and deep learning models, as well as interpreting their predictions. However, recent advances in adversarial machine learning (AdvML) highlight the limitations and vulnerabilities of state-of-the-art explanation methods, putting their security and trustworthiness into question. The possibility of manipulating, fooling or fairwashing evidence of the model's reasoning has detrimental consequences when applied in high-stakes decision-making and knowledge discovery. This survey provides a comprehensive overview of research concerning adversarial attacks on explanations of machine learning models, as well as fairness metrics. We introduce a unified notation and taxonomy of methods facilitating a common ground for researchers and practitioners from the intersecting research fields of AdvML and XAI. We discuss how to defend against attacks and design robust interpretation methods. We contribute a list of existing insecurities in XAI and outline the emerging research directions in adversarial XAI (AdvXAI). Future work should address improving explanation methods and evaluation protocols to take into account the reported safety issues.
PDF Abstract

 ImageNet
ImageNet
 MNIST
MNIST
