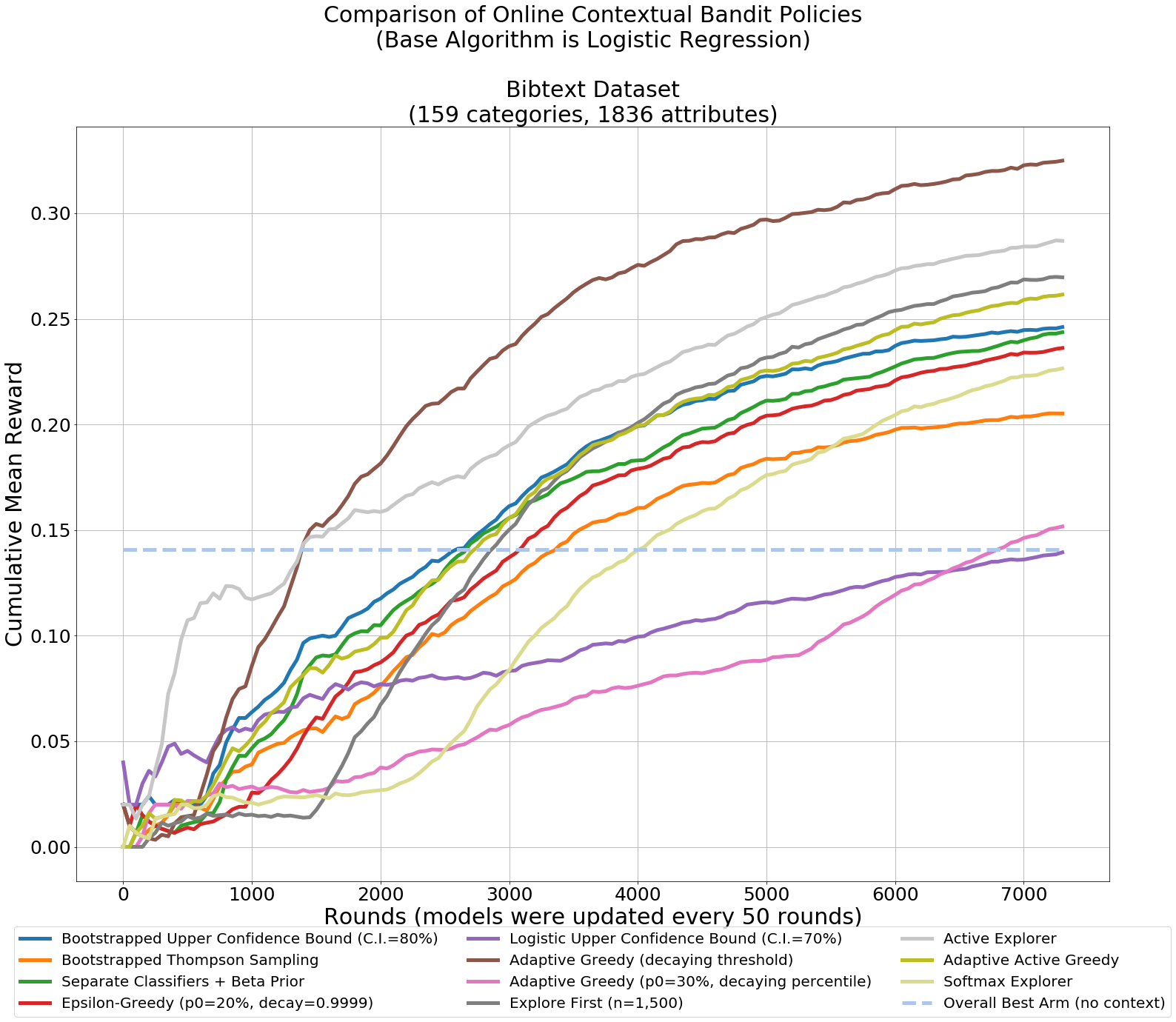
Adapting multi-armed bandits policies to contextual bandits scenarios
This work explores adaptations of successful multi-armed bandits policies to the online contextual bandits scenario with binary rewards using binary classification algorithms such as logistic regression as black-box oracles. Some of these adaptations are achieved through bootstrapping or approximate bootstrapping, while others rely on other forms of randomness, resulting in more scalable approaches than previous works, and the ability to work with any type of classification algorithm. In particular, the Adaptive-Greedy algorithm shows a lot of promise, in many cases achieving better performance than upper confidence bound and Thompson sampling strategies, at the expense of more hyperparameters to tune.
PDF Abstract



Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
