Active Inverse Reward Design
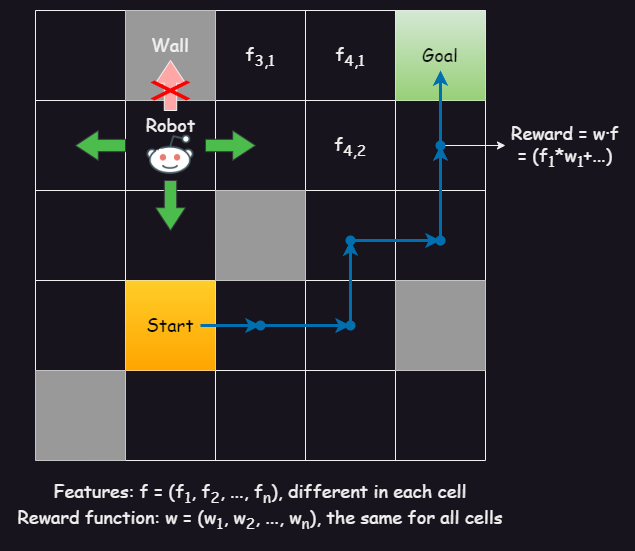
Designers of AI agents often iterate on the reward function in a trial-and-error process until they get the desired behavior, but this only guarantees good behavior in the training environment. We propose structuring this process as a series of queries asking the user to compare between different reward functions. Thus we can actively select queries for maximum informativeness about the true reward. In contrast to approaches asking the designer for optimal behavior, this allows us to gather additional information by eliciting preferences between suboptimal behaviors. After each query, we need to update the posterior over the true reward function from observing the proxy reward function chosen by the designer. The recently proposed Inverse Reward Design (IRD) enables this. Our approach substantially outperforms IRD in test environments. In particular, it can query the designer about interpretable, linear reward functions and still infer non-linear ones.
PDF Abstract

