Action Recognition for Depth Video using Multi-view Dynamic Images
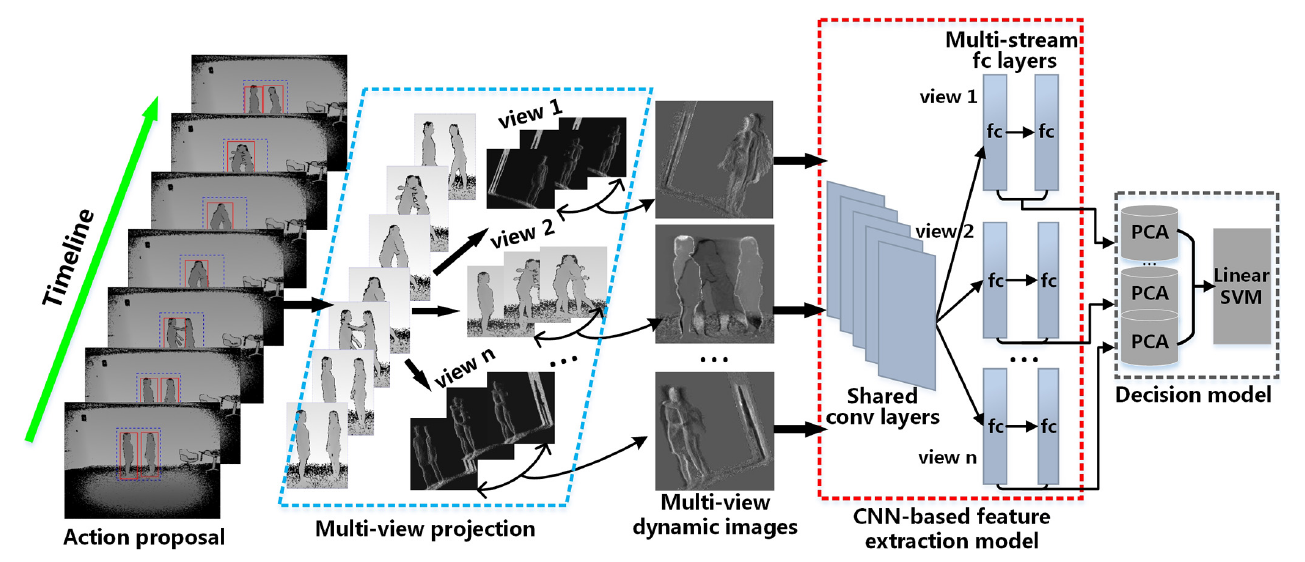
Dynamic imaging is a recently proposed action description paradigm for simultaneously capturing motion and temporal evolution information, particularly in the context of deep convolutional neural networks (CNNs). Compared with optical flow for motion characterization, dynamic imaging exhibits superior efficiency and compactness. Inspired by the success of dynamic imaging in RGB video, this study extends it to the depth domain. To better exploit three-dimensional (3D) characteristics, multi-view dynamic images are proposed. In particular, the raw depth video is densely projected with respect to different virtual imaging viewpoints by rotating the virtual camera within the 3D space. Subsequently, dynamic images are extracted from the obtained multi-view depth videos and multi-view dynamic images are thus constructed from these images. Accordingly, more view-tolerant visual cues can be involved. A novel CNN model is then proposed to perform feature learning on multi-view dynamic images. Particularly, the dynamic images from different views share the same convolutional layers but correspond to different fully connected layers. This is aimed at enhancing the tuning effectiveness on shallow convolutional layers by alleviating the gradient vanishing problem. Moreover, as the spatial occurrence variation of the actions may impair the CNN, an action proposal approach is also put forth. In experiments, the proposed approach can achieve state-of-the-art performance on three challenging datasets.
PDF Abstract


 NTU RGB+D
NTU RGB+D
