Accurate LoRA-Finetuning Quantization of LLMs via Information Retention
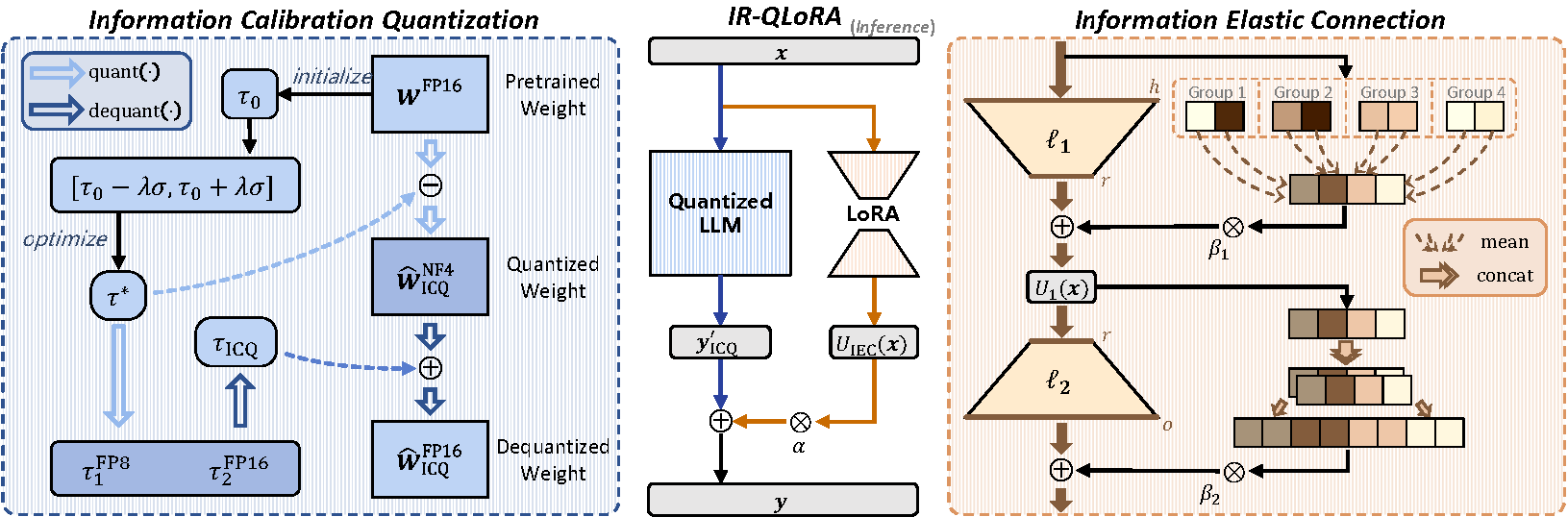
The LoRA-finetuning quantization of LLMs has been extensively studied to obtain accurate yet compact LLMs for deployment on resource-constrained hardware. However, existing methods cause the quantized LLM to severely degrade and even fail to benefit from the finetuning of LoRA. This paper proposes a novel IR-QLoRA for pushing quantized LLMs with LoRA to be highly accurate through information retention. The proposed IR-QLoRA mainly relies on two technologies derived from the perspective of unified information: (1) statistics-based Information Calibration Quantization allows the quantized parameters of LLM to retain original information accurately; (2) finetuning-based Information Elastic Connection makes LoRA utilizes elastic representation transformation with diverse information. Comprehensive experiments show that IR-QLoRA can significantly improve accuracy across LLaMA and LLaMA2 families under 2-4 bit-widths, e.g., 4- bit LLaMA-7B achieves 1.4% improvement on MMLU compared with the state-of-the-art methods. The significant performance gain requires only a tiny 0.31% additional time consumption, revealing the satisfactory efficiency of our IRQLoRA. We highlight that IR-QLoRA enjoys excellent versatility, compatible with various frameworks (e.g., NormalFloat and Integer quantization) and brings general accuracy gains. The code is available at https://github.com/htqin/ir-qlora.
PDF Abstract

 MMLU
MMLU
 HellaSwag
HellaSwag
 PIQA
PIQA
