A Versatile Framework for Multi-scene Person Re-identification
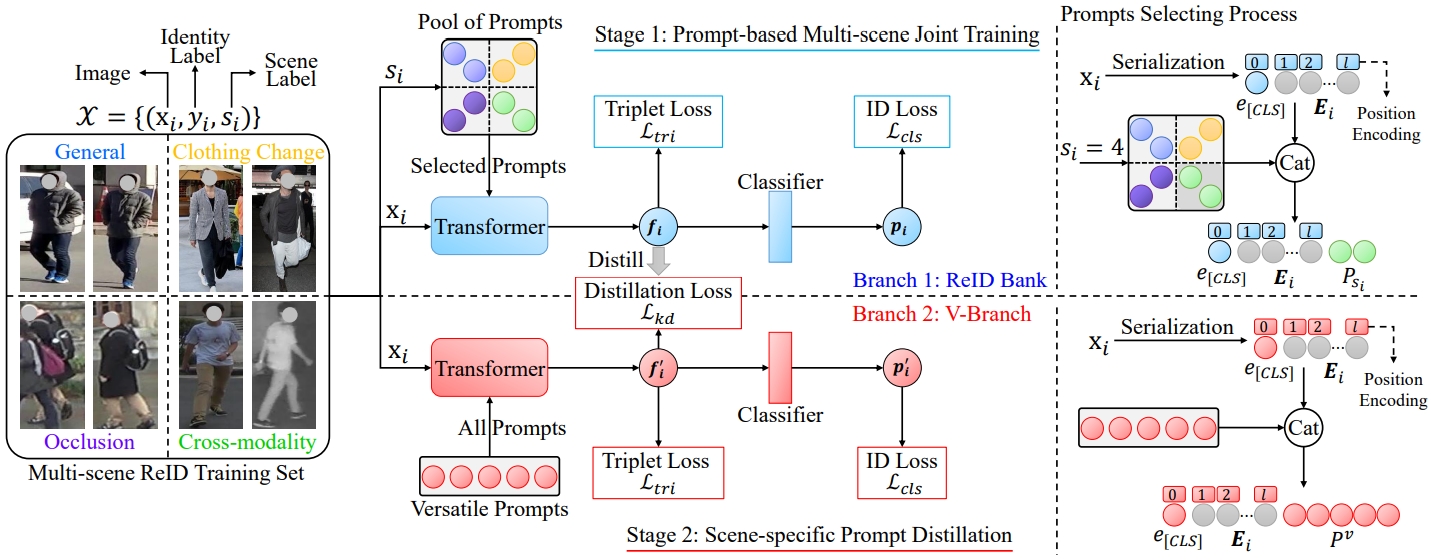
Person Re-identification (ReID) has been extensively developed for a decade in order to learn the association of images of the same person across non-overlapping camera views. To overcome significant variations between images across camera views, mountains of variants of ReID models were developed for solving a number of challenges, such as resolution change, clothing change, occlusion, modality change, and so on. Despite the impressive performance of many ReID variants, these variants typically function distinctly and cannot be applied to other challenges. To our best knowledge, there is no versatile ReID model that can handle various ReID challenges at the same time. This work contributes to the first attempt at learning a versatile ReID model to solve such a problem. Our main idea is to form a two-stage prompt-based twin modeling framework called VersReID. Our VersReID firstly leverages the scene label to train a ReID Bank that contains abundant knowledge for handling various scenes, where several groups of scene-specific prompts are used to encode different scene-specific knowledge. In the second stage, we distill a V-Branch model with versatile prompts from the ReID Bank for adaptively solving the ReID of different scenes, eliminating the demand for scene labels during the inference stage. To facilitate training VersReID, we further introduce the multi-scene properties into self-supervised learning of ReID via a multi-scene prioris data augmentation (MPDA) strategy. Through extensive experiments, we demonstrate the success of learning an effective and versatile ReID model for handling ReID tasks under multi-scene conditions without manual assignment of scene labels in the inference stage, including general, low-resolution, clothing change, occlusion, and cross-modality scenes. Codes and models are available at https://github.com/iSEE-Laboratory/VersReID.
PDF Abstract



