A Survey of Online Experiment Design with the Stochastic Multi-Armed Bandit
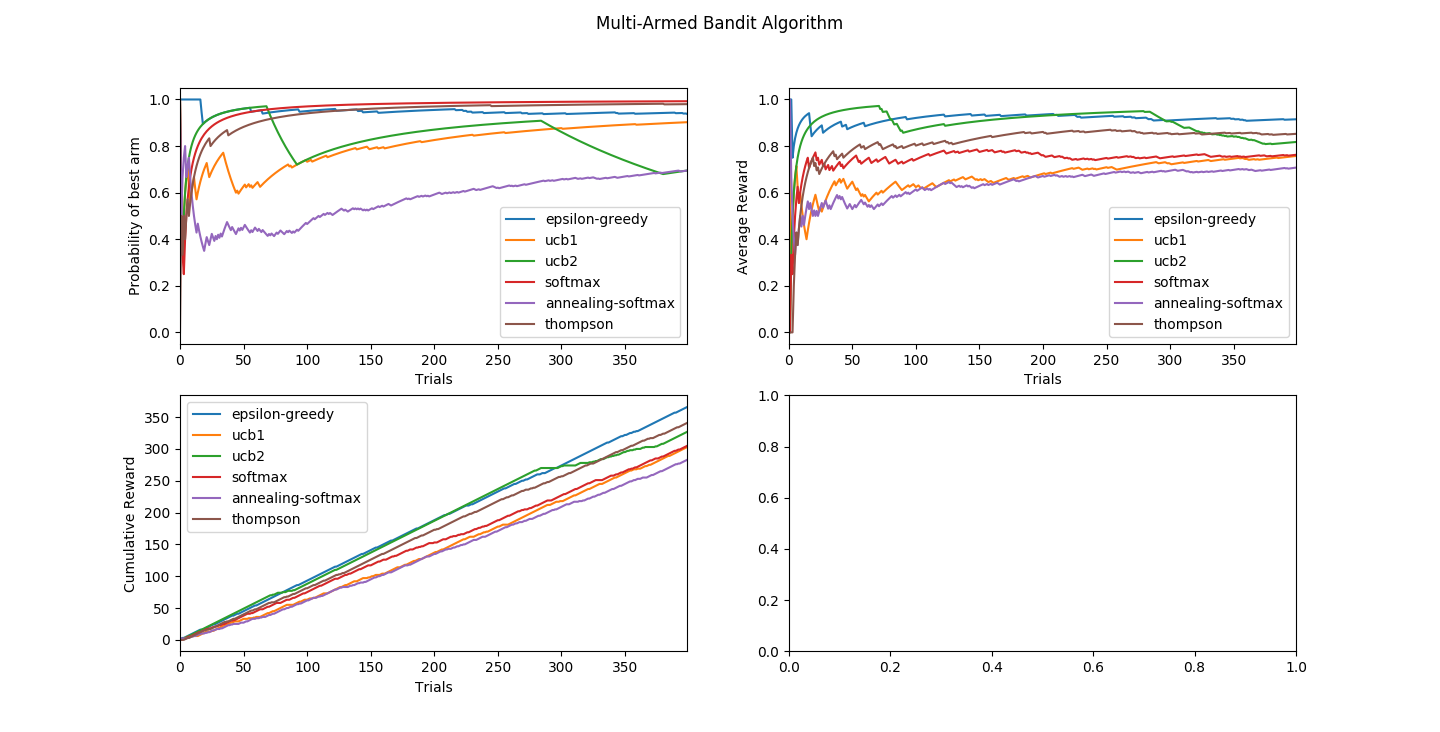
Adaptive and sequential experiment design is a well-studied area in numerous domains. We survey and synthesize the work of the online statistical learning paradigm referred to as multi-armed bandits integrating the existing research as a resource for a certain class of online experiments. We first explore the traditional stochastic model of a multi-armed bandit, then explore a taxonomic scheme of complications to that model, for each complication relating it to a specific requirement or consideration of the experiment design context. Finally, at the end of the paper, we present a table of known upper-bounds of regret for all studied algorithms providing both perspectives for future theoretical work and a decision-making tool for practitioners looking for theoretical guarantees.
PDF Abstract

