A Semantic Space is Worth 256 Language Descriptions: Make Stronger Segmentation Models with Descriptive Properties
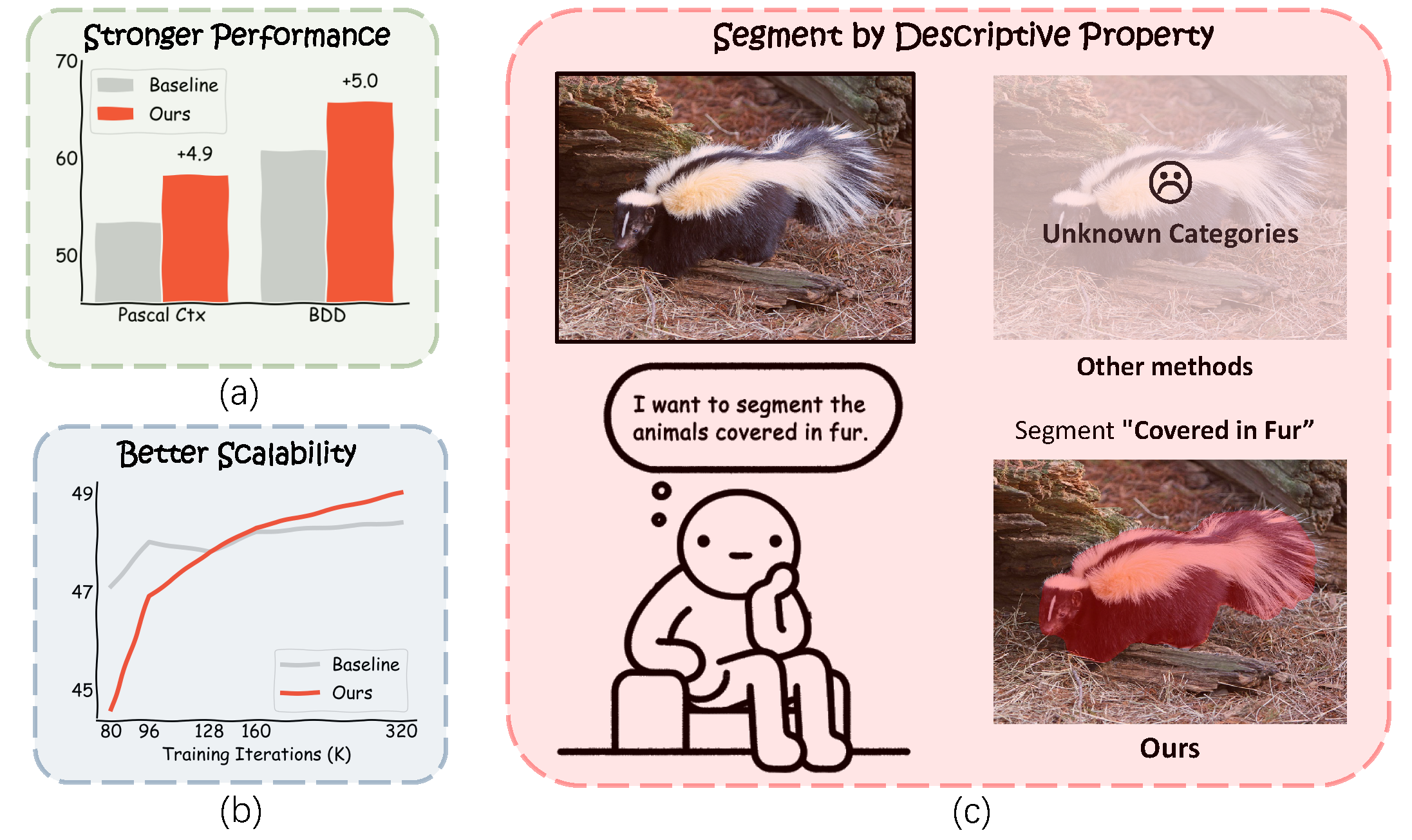
This paper introduces ProLab, a novel approach using property-level label space for creating strong interpretable segmentation models. Instead of relying solely on category-specific annotations, ProLab uses descriptive properties grounded in common sense knowledge for supervising segmentation models. It is based on two core designs. First, we employ Large Language Models (LLMs) and carefully crafted prompts to generate descriptions of all involved categories that carry meaningful common sense knowledge and follow a structured format. Second, we introduce a description embedding model preserving semantic correlation across descriptions and then cluster them into a set of descriptive properties (e.g., 256) using K-Means. These properties are based on interpretable common sense knowledge consistent with theories of human recognition. We empirically show that our approach makes segmentation models perform stronger on five classic benchmarks (e.g., ADE20K, COCO-Stuff, Pascal Context, Cityscapes, and BDD). Our method also shows better scalability with extended training steps than category-level supervision. Our interpretable segmentation framework also emerges with the generalization ability to segment out-of-domain or unknown categories using only in-domain descriptive properties. Code is available at https://github.com/lambert-x/ProLab.
PDF Abstract

 Cityscapes
Cityscapes
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
