A Revisit of Hashing Algorithms for Approximate Nearest Neighbor Search
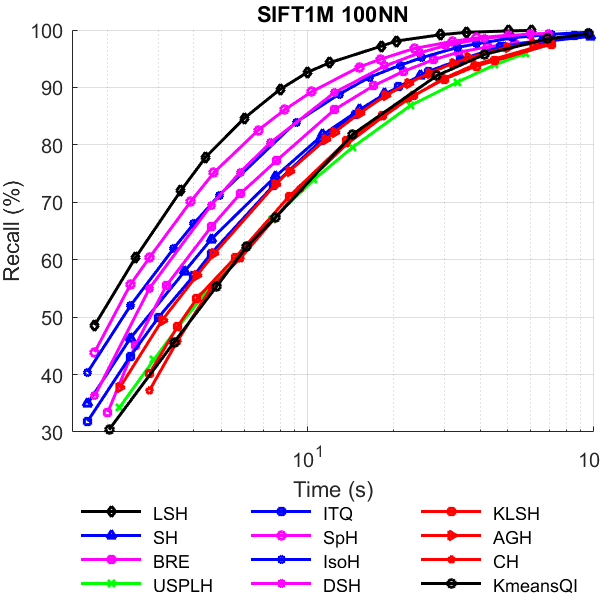
Approximate Nearest Neighbor Search (ANNS) is a fundamental problem in many areas of machine learning and data mining. During the past decade, numerous hashing algorithms are proposed to solve this problem. Every proposed algorithm claims outperform other state-of-the-art hashing methods. However, the evaluation of these hashing papers was not thorough enough, and those claims should be re-examined. The ultimate goal of an ANNS method is returning the most accurate answers (nearest neighbors) in the shortest time. If implemented correctly, almost all the hashing methods will have their performance improved as the code length increases. However, many existing hashing papers only report the performance with the code length shorter than 128. In this paper, we carefully revisit the problem of search with a hash index, and analyze the pros and cons of two popular hash index search procedures. Then we proposed a very simple but effective two level index structures and make a thorough comparison of eleven popular hashing algorithms. Surprisingly, the random-projection-based Locality Sensitive Hashing (LSH) is the best performed algorithm, which is in contradiction to the claims in all the other ten hashing papers. Despite the extreme simplicity of random-projection-based LSH, our results show that the capability of this algorithm has been far underestimated. For the sake of reproducibility, all the codes used in the paper are released on GitHub, which can be used as a testing platform for a fair comparison between various hashing algorithms.
PDF Abstract