A Layer-Wise Tokens-to-Token Transformer Network for Improved Historical Document Image Enhancement
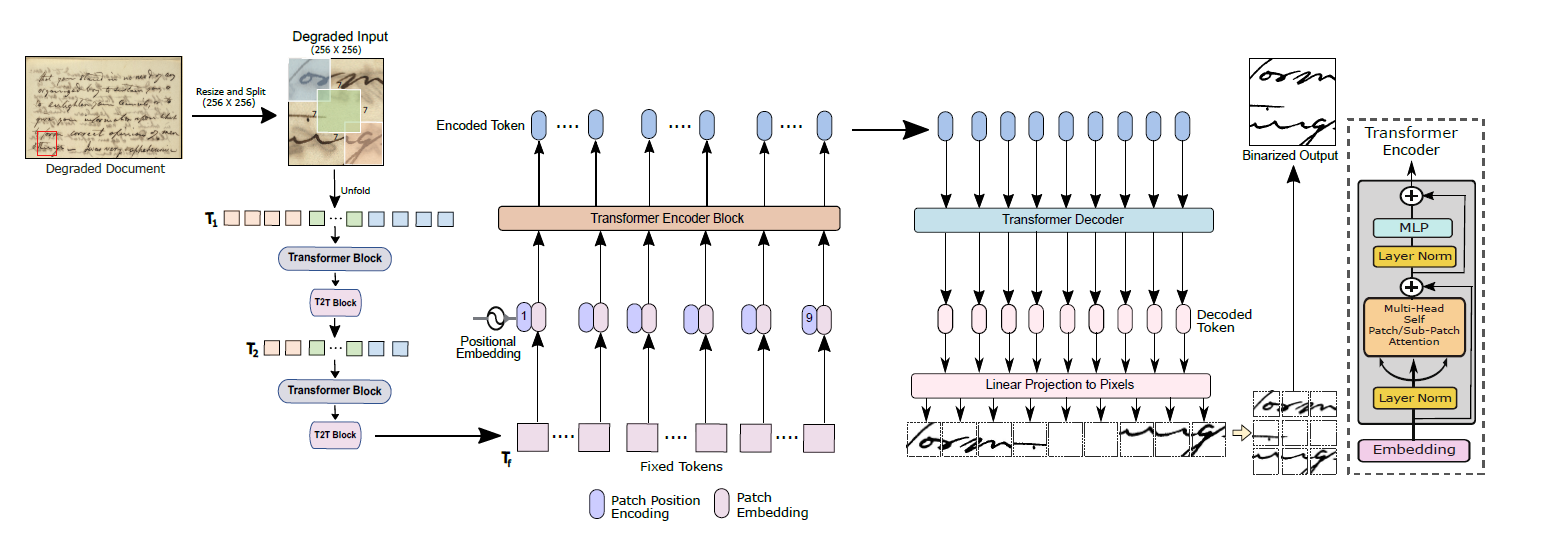
Document image enhancement is a fundamental and important stage for attaining the best performance in any document analysis assignment because there are many degradation situations that could harm document images, making it more difficult to recognize and analyze them. In this paper, we propose \textbf{T2T-BinFormer} which is a novel document binarization encoder-decoder architecture based on a Tokens-to-token vision transformer. Each image is divided into a set of tokens with a defined length using the ViT model, which is then applied several times to model the global relationship between the tokens. However, the conventional tokenization of input data does not adequately reflect the crucial local structure between adjacent pixels of the input image, which results in low efficiency. Instead of using a simple ViT and hard splitting of images for the document image enhancement task, we employed a progressive tokenization technique to capture this local information from an image to achieve more effective results. Experiments on various DIBCO and H-DIBCO benchmarks demonstrate that the proposed model outperforms the existing CNN and ViT-based state-of-the-art methods. In this research, the primary area of examination is the application of the proposed architecture to the task of document binarization. The source code will be made available at https://github.com/RisabBiswas/T2T-BinFormer.
PDF Abstract

