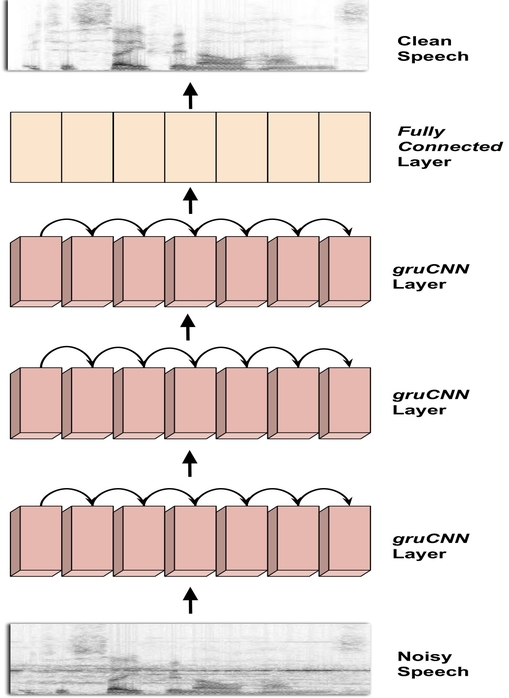
A fully recurrent feature extraction for single channel speech enhancement
Convolutional neural network (CNN) modules are widely being used to build high-end speech enhancement neural models. However, the feature extraction power of vanilla CNN modules has been limited by the dimensionality constraint of the convolution kernels that are integrated - thereby, they have limitations to adequately model the noise context information at the feature extraction stage. To this end, adding recurrency factor into the feature extracting CNN layers, we introduce a robust context-aware feature extraction strategy for single-channel speech enhancement. As shown, adding recurrency results in capturing the local statistics of noise attributes at the extracted features level and thus, the suggested model is effective in differentiating speech cues even at very noisy conditions. When evaluated against enhancement models using vanilla CNN modules, in unseen noise conditions, the suggested model with recurrency in the feature extraction layers has produced a segmental SNR (SSNR) gain of up to 1.5 dB, an improvement of 0.4 in subjective quality in the Mean Opinion Score scale, while the parameters to be optimized are reduced by 25%.
PDF Abstract arXiv 2020 PDF arXiv 2020 Abstract

