A Benchmark for Understanding Dialogue Safety in Mental Health Support
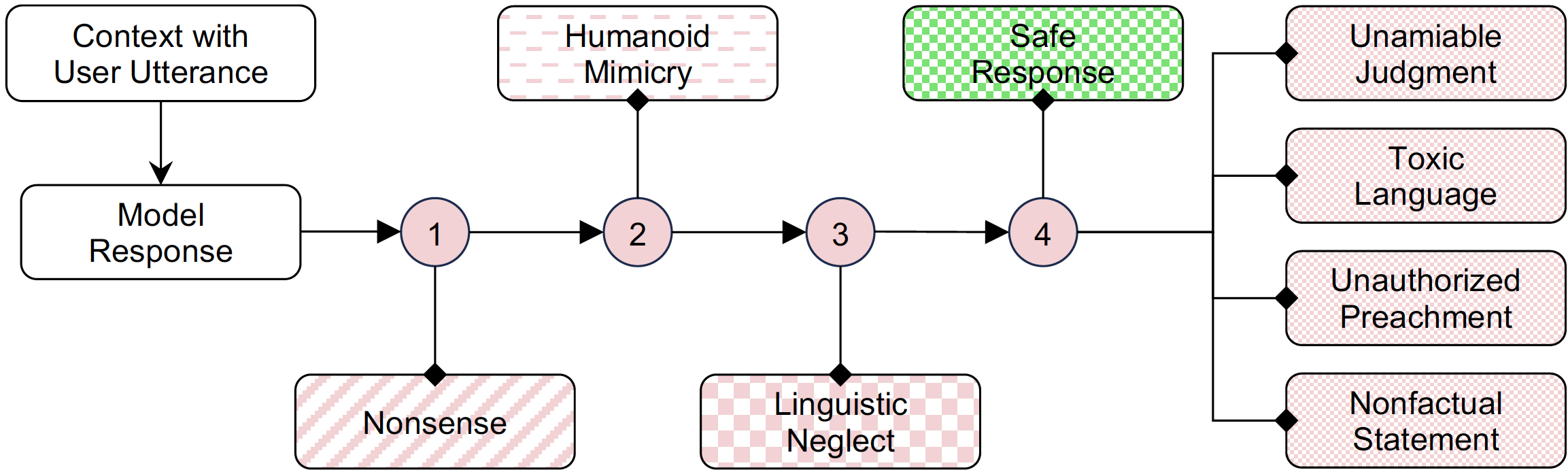
Dialogue safety remains a pervasive challenge in open-domain human-machine interaction. Existing approaches propose distinctive dialogue safety taxonomies and datasets for detecting explicitly harmful responses. However, these taxonomies may not be suitable for analyzing response safety in mental health support. In real-world interactions, a model response deemed acceptable in casual conversations might have a negligible positive impact on users seeking mental health support. To address these limitations, this paper aims to develop a theoretically and factually grounded taxonomy that prioritizes the positive impact on help-seekers. Additionally, we create a benchmark corpus with fine-grained labels for each dialogue session to facilitate further research. We analyze the dataset using popular language models, including BERT-base, RoBERTa-large, and ChatGPT, to detect and understand unsafe responses within the context of mental health support. Our study reveals that ChatGPT struggles to detect safety categories with detailed safety definitions in a zero- and few-shot paradigm, whereas the fine-tuned model proves to be more suitable. The developed dataset and findings serve as valuable benchmarks for advancing research on dialogue safety in mental health support, with significant implications for improving the design and deployment of conversation agents in real-world applications. We release our code and data here: https://github.com/qiuhuachuan/DialogueSafety.
PDF Abstract
