3D-EffiViTCaps: 3D Efficient Vision Transformer with Capsule for Medical Image Segmentation
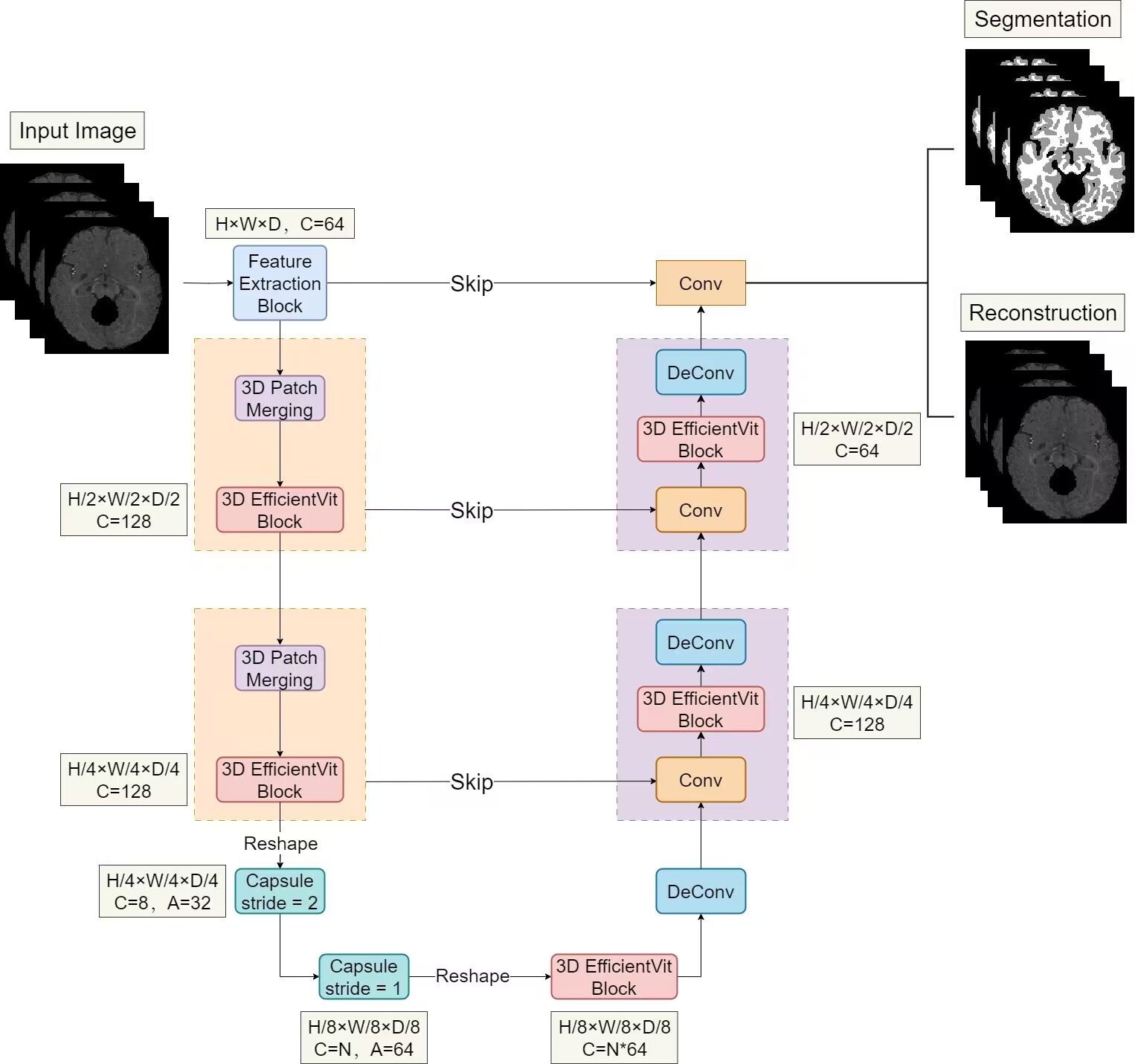
Medical image segmentation (MIS) aims to finely segment various organs. It requires grasping global information from both parts and the entire image for better segmenting, and clinically there are often certain requirements for segmentation efficiency. Convolutional neural networks (CNNs) have made considerable achievements in MIS. However, they are difficult to fully collect global context information and their pooling layer may cause information loss. Capsule networks, which combine the benefits of CNNs while taking into account additional information such as relative location that CNNs do not, have lately demonstrated some advantages in MIS. Vision Transformer (ViT) employs transformers in visual tasks. Transformer based on attention mechanism has excellent global inductive modeling capabilities and is expected to capture longrange information. Moreover, there have been resent studies on making ViT more lightweight to minimize model complexity and increase efficiency. In this paper, we propose a U-shaped 3D encoder-decoder network named 3D-EffiViTCaps, which combines 3D capsule blocks with 3D EfficientViT blocks for MIS. Our encoder uses capsule blocks and EfficientViT blocks to jointly capture local and global semantic information more effectively and efficiently with less information loss, while the decoder employs CNN blocks and EfficientViT blocks to catch ffner details for segmentation. We conduct experiments on various datasets, including iSeg-2017, Hippocampus and Cardiac to verify the performance and efficiency of 3D-EffiViTCaps, which performs better than previous 3D CNN-based, 3D Capsule-based and 3D Transformer-based models. We further implement a series of ablation experiments on the main blocks. Our code is available at: https://github.com/HidNeuron/3D-EffiViTCaps.
PDF Abstract



