TinyBERT: Distilling BERT for Natural Language Understanding
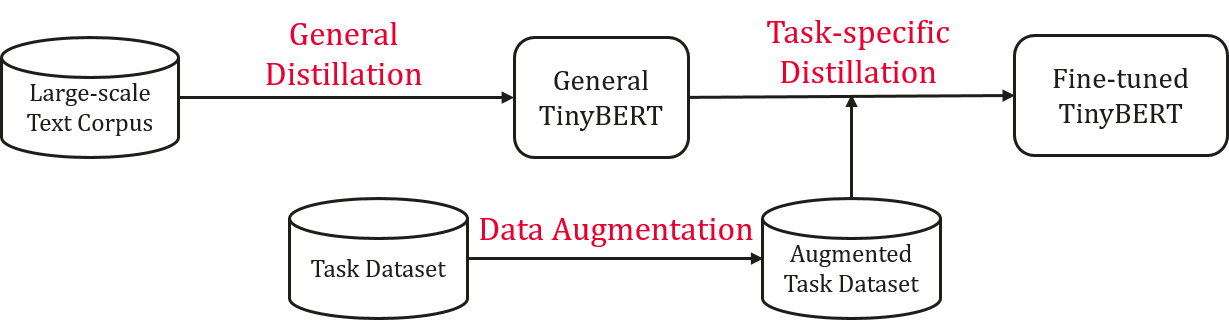
Language model pre-training, such as BERT, has significantly improved the performances of many natural language processing tasks. However, pre-trained language models are usually computationally expensive, so it is difficult to efficiently execute them on resource-restricted devices. To accelerate inference and reduce model size while maintaining accuracy, we first propose a novel Transformer distillation method that is specially designed for knowledge distillation (KD) of the Transformer-based models. By leveraging this new KD method, the plenty of knowledge encoded in a large teacher BERT can be effectively transferred to a small student Tiny-BERT. Then, we introduce a new two-stage learning framework for TinyBERT, which performs Transformer distillation at both the pretraining and task-specific learning stages. This framework ensures that TinyBERT can capture he general-domain as well as the task-specific knowledge in BERT. TinyBERT with 4 layers is empirically effective and achieves more than 96.8% the performance of its teacher BERTBASE on GLUE benchmark, while being 7.5x smaller and 9.4x faster on inference. TinyBERT with 4 layers is also significantly better than 4-layer state-of-the-art baselines on BERT distillation, with only about 28% parameters and about 31% inference time of them. Moreover, TinyBERT with 6 layers performs on-par with its teacher BERTBASE.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract










 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
 Quora
Quora
 Quora Question Pairs
Quora Question Pairs

