Automatic and Simultaneous Adjustment of Learning Rate and Momentum for Stochastic Gradient Descent
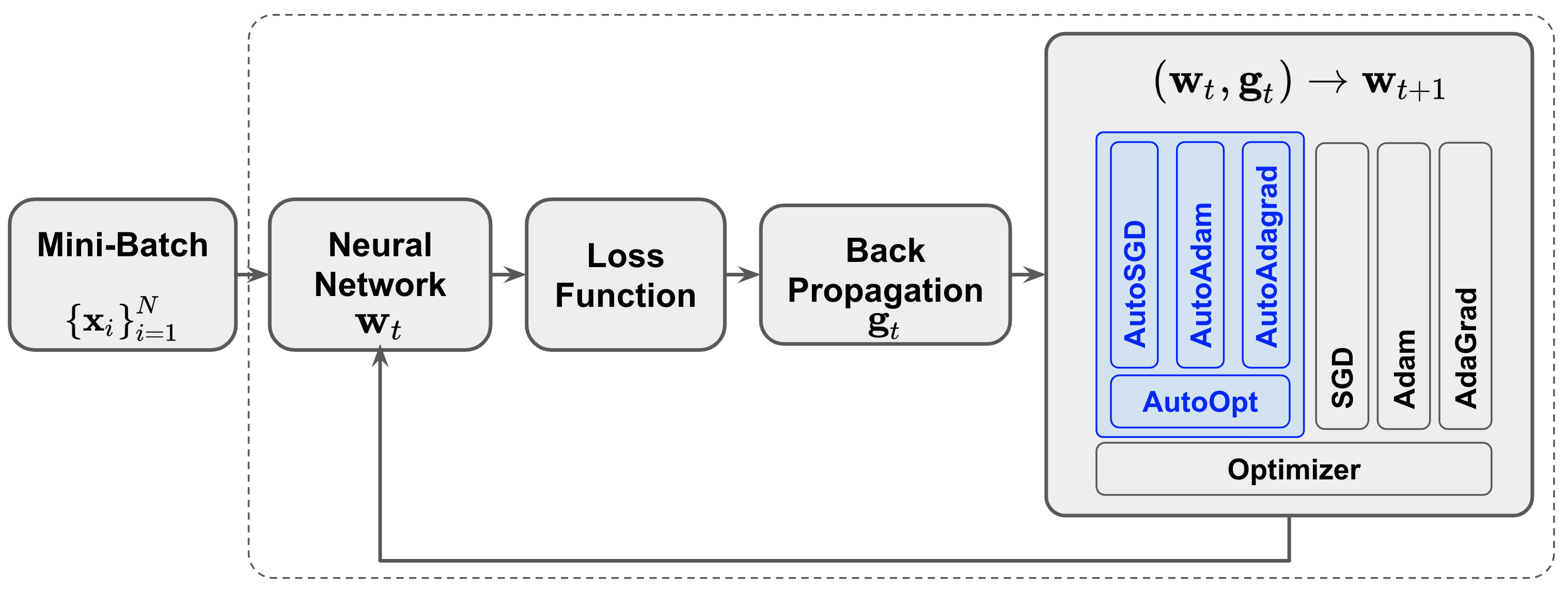
Stochastic Gradient Descent (SGD) methods are prominent for training machine learning and deep learning models. The performance of these techniques depends on their hyperparameter tuning over time and varies for different models and problems. Manual adjustment of hyperparameters is very costly and time-consuming, and even if done correctly, it lacks theoretical justification which inevitably leads to "rule of thumb" settings. In this paper, we propose a generic approach that utilizes the statistics of an unbiased gradient estimator to automatically and simultaneously adjust two paramount hyperparameters: the learning rate and momentum. We deploy the proposed general technique for various SGD methods to train Convolutional Neural Networks (CNN's). The results match the performance of the best settings obtained through an exhaustive search and therefore, removes the need for a tedious manual tuning.
PDF Abstract
 CIFAR-10
CIFAR-10
