 Text-to-Speech Models
Text-to-Speech Models
WaveTTS
Introduced by Liu et al. in WaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain LossWaveTTS is a Tacotron-based text-to-speech architecture that has two loss functions: 1) time-domain loss, denoted as the waveform loss, that measures the distortion between the natural and generated waveform; and 2) frequency-domain loss, that measures the Mel-scale acoustic feature loss between the natural and generated acoustic features.
The motivation arises from Tacotron 2. Here its feature prediction network is trained independently of the WaveNet vocoder. At run-time, the feature prediction network and WaveNet vocoder are artificially joined together. As a result, the framework suffers from the mismatch between frequency-domain acoustic features and time-domain waveform. To overcome such mismatch, WaveTTS uses a joint time-frequency domain loss for TTS that effectively improves the synthesized voice quality.
Source: WaveTTS: Tacotron-based TTS with Joint Time-Frequency Domain Loss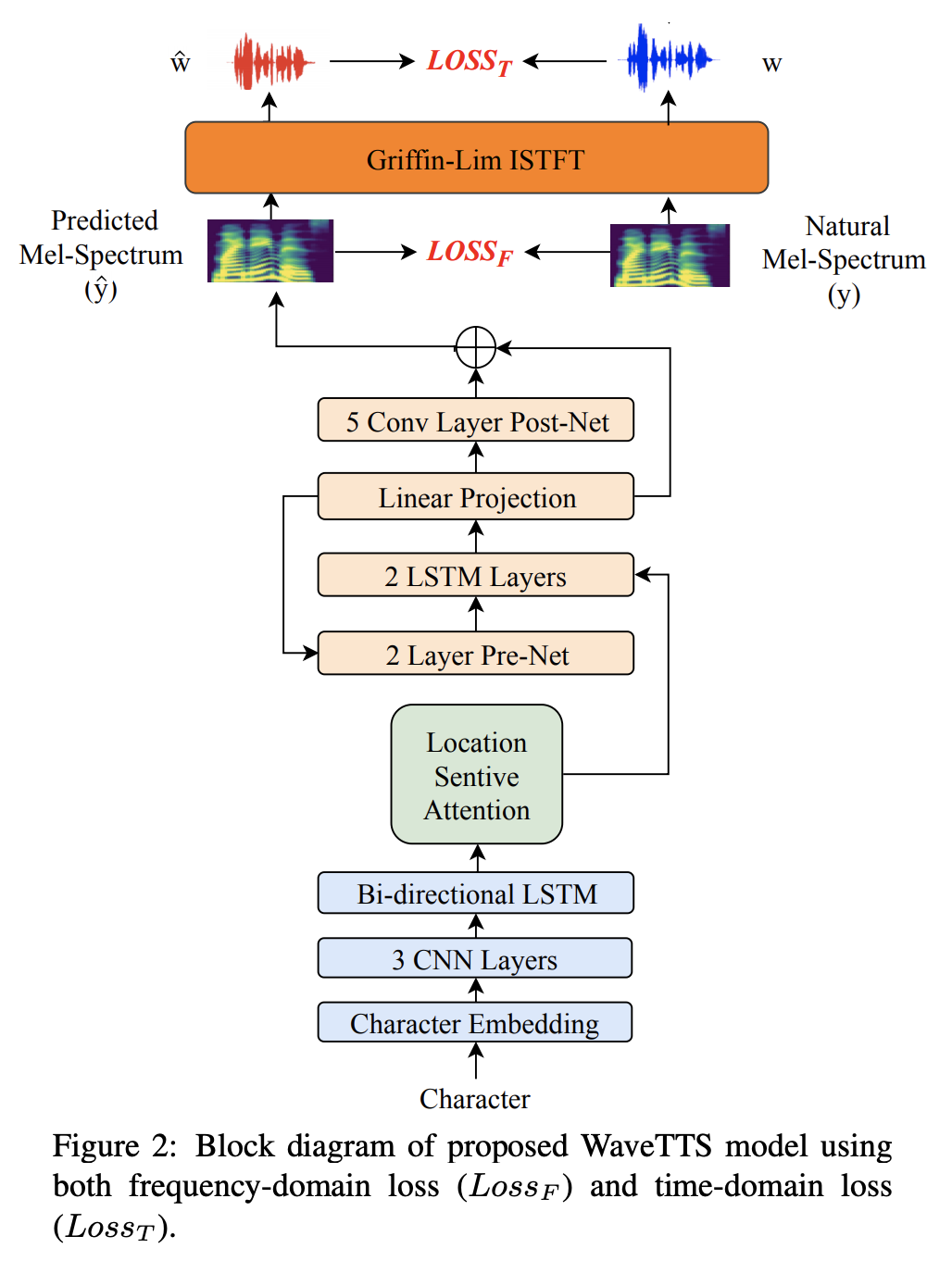
Papers
| Paper | Code | Results | Date | Stars |
|---|
 BiLSTM
BiLSTM
 Convolution
Convolution
 Griffin-Lim Algorithm
Griffin-Lim Algorithm
 Location Sensitive Attention
Location Sensitive Attention
 ReLU
ReLU
 WaveNet
WaveNet
