 Language Models
Language Models
Universal Language Model Fine-tuning
Introduced by Howard et al. in Universal Language Model Fine-tuning for Text ClassificationUniversal Language Model Fine-tuning, or ULMFiT, is an architecture and transfer learning method that can be applied to NLP tasks. It involves a 3-layer AWD-LSTM architecture for its representations. The training consists of three steps: 1) general language model pre-training on a Wikipedia-based text, 2) fine-tuning the language model on a target task, and 3) fine-tuning the classifier on the target task.
As different layers capture different types of information, they are fine-tuned to different extents using discriminative fine-tuning. Training is performed using Slanted triangular learning rates (STLR), a learning rate scheduling strategy that first linearly increases the learning rate and then linearly decays it.
Fine-tuning the target classifier is achieved in ULMFiT using gradual unfreezing. Rather than fine-tuning all layers at once, which risks catastrophic forgetting, ULMFiT gradually unfreezes the model starting from the last layer (i.e., closest to the output) as this contains the least general knowledge. First the last layer is unfrozen and all unfrozen layers are fine-tuned for one epoch. Then the next group of frozen layers is unfrozen and fine-tuned and repeat, until all layers are fine-tuned until convergence at the last iteration.
Source: Universal Language Model Fine-tuning for Text Classification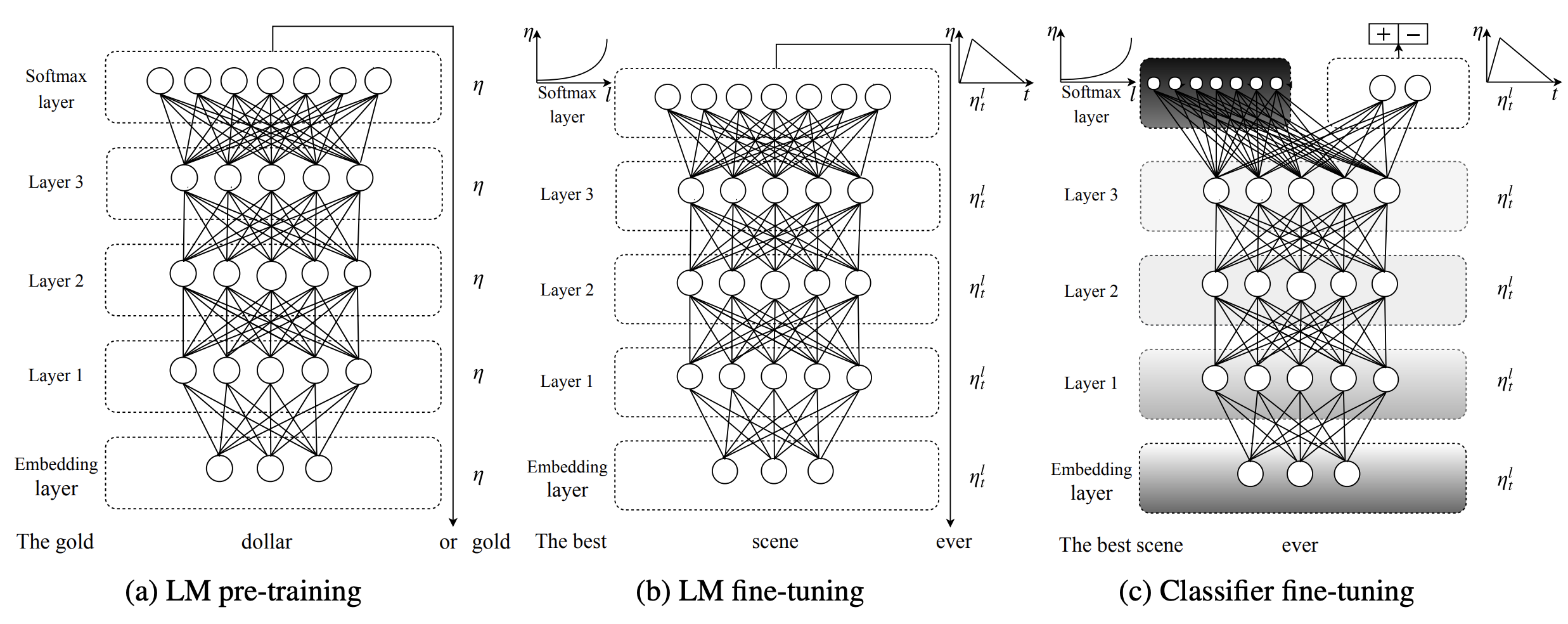
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 12 | 15.00% |
| General Classification | 12 | 15.00% |
| Text Classification | 10 | 12.50% |
| Sentiment Analysis | 8 | 10.00% |
| Classification | 7 | 8.75% |
| Hate Speech Detection | 3 | 3.75% |
| Marketing | 2 | 2.50% |
| Transliteration | 2 | 2.50% |
| Language Identification | 2 | 2.50% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
 AWD-LSTM
AWD-LSTM
|
Recurrent Neural Networks | |
 Discriminative Fine-Tuning
Discriminative Fine-Tuning
|
Fine-Tuning | |
 Slanted Triangular Learning Rates
Slanted Triangular Learning Rates
|
Learning Rate Schedules |
