 Transformers
Transformers
Performer
Introduced by Choromanski et al. in Rethinking Attention with PerformersPerformer is a Transformer architectures which can estimate regular (softmax) full-rank-attention Transformers with provable accuracy, but using only linear (as opposed to quadratic) space and time complexity, without relying on any priors such as sparsity or low-rankness. Performers are linear architectures fully compatible with regular Transformers and with strong theoretical guarantees: unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence and low estimation variance. To approximate softmax attention-kernels, Performers use a Fast Attention Via positive Orthogonal Random features approach (FAVOR+), leveraging new methods for approximating softmax and Gaussian kernels.
Source: Rethinking Attention with Performers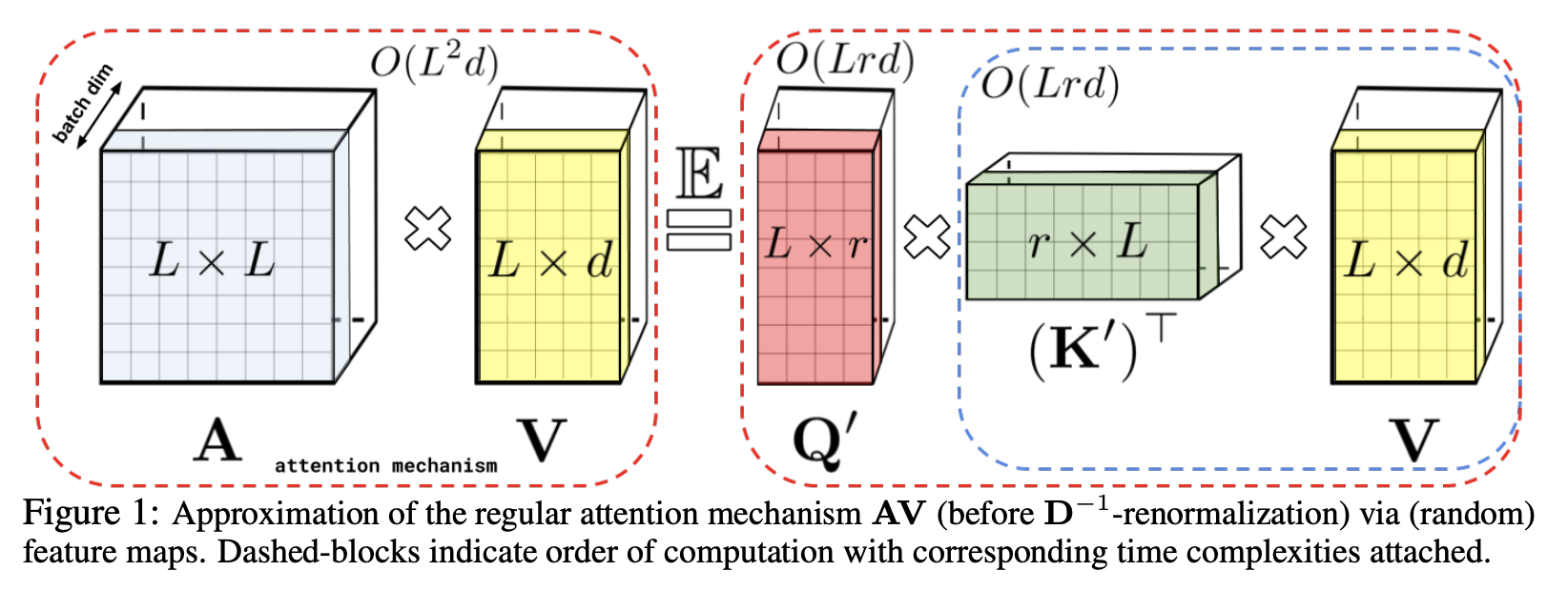
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Language Modelling | 5 | 5.32% |
| Time Series Analysis | 4 | 4.26% |
| Image Classification | 3 | 3.19% |
| Novel View Synthesis | 3 | 3.19% |
| Classification | 3 | 3.19% |
| Anomaly Detection | 2 | 2.13% |
| Dynamic Time Warping | 2 | 2.13% |
| Image Generation | 2 | 2.13% |
| Time Series Anomaly Detection | 2 | 2.13% |
 FAVOR+
FAVOR+
