WikiReading
Introduced by Hewlett et al. in WikiReading: A Novel Large-scale Language Understanding Task over Wikipedia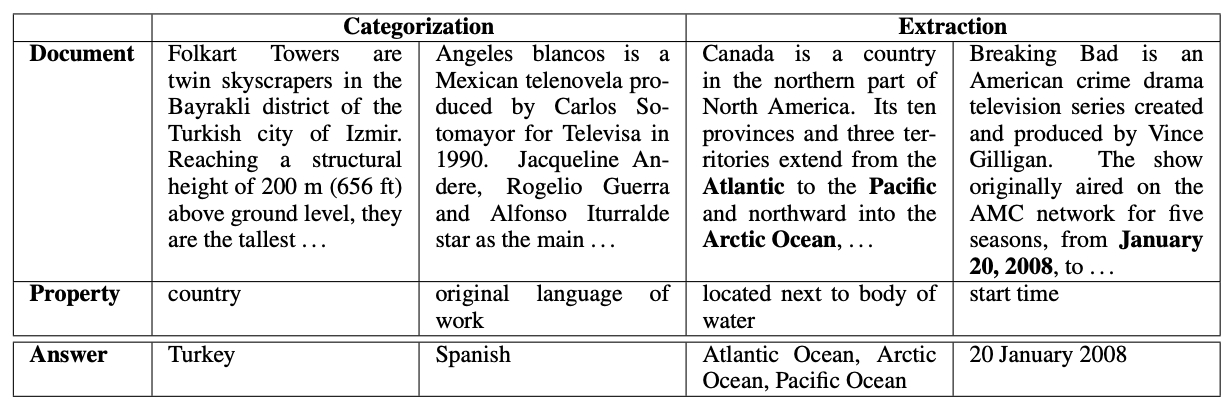
WikiReading is a large-scale natural language understanding task and publicly-available dataset with 18 million instances. The task is to predict textual values from the structured knowledge base Wikidata by reading the text of the corresponding Wikipedia articles. The task contains a rich variety of challenging classification and extraction sub-tasks, making it well-suited for end-to-end models such as deep neural networks (DNNs).
Source: WIKIREADING: A Novel Large-scale Language Understanding Task over WikipediaPapers
| Paper | Code | Results | Date | Stars |
|---|




