SemEval-2014 Task-10
Introduced by Agirre et al. in SemEval-2014 Task 10: Multilingual Semantic Textual Similarity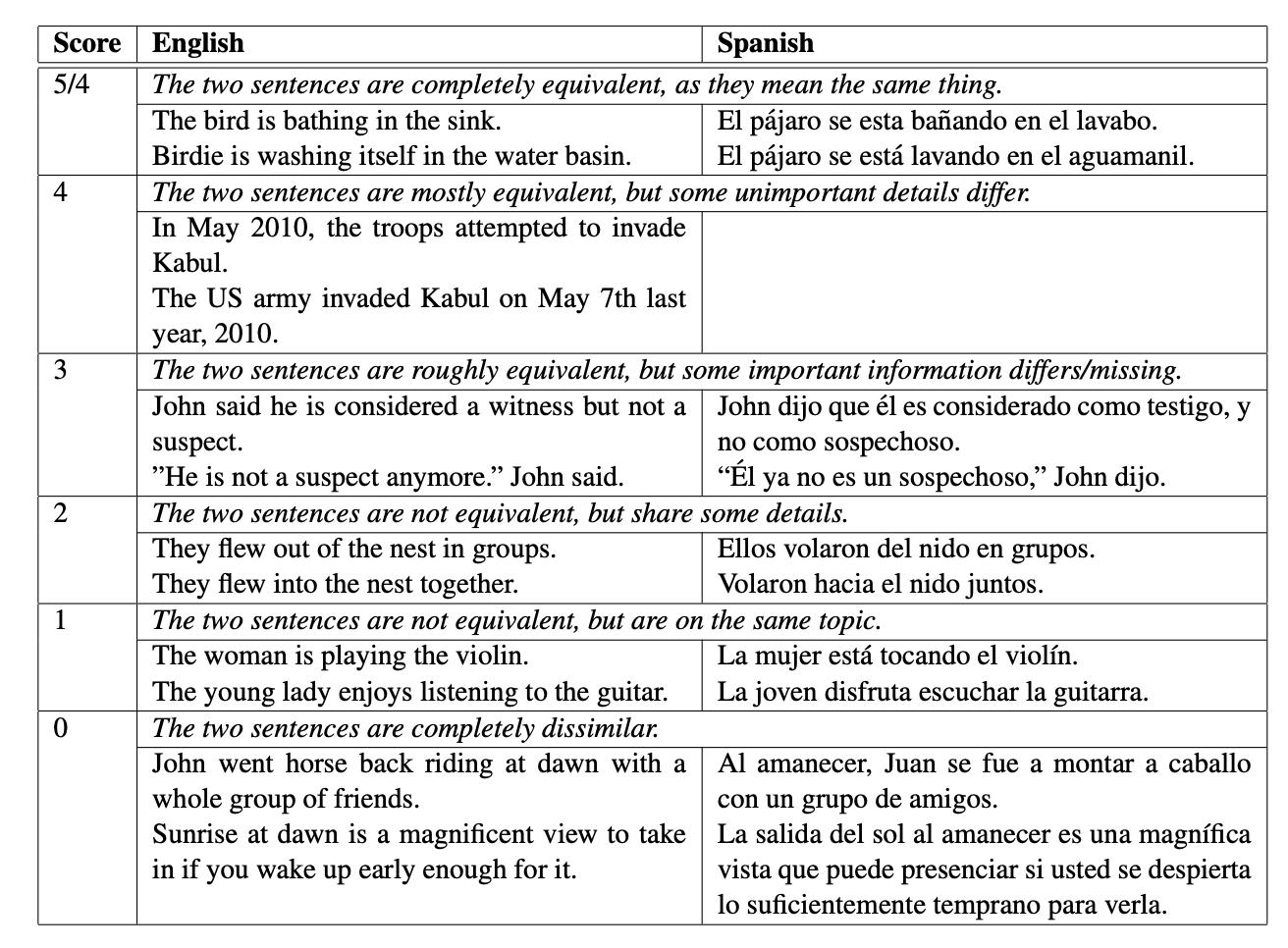
SemEval 2014 is a collection of datasets used for the Semantic Evaluation (SemEval) workshop, an annual event that focuses on the evaluation and comparison of systems that can analyze diverse semantic phenomena in text. The datasets from SemEval 2014 are used for various tasks, including but not limited to:
- Aspect-Based Sentiment Analysis (ABSA): This task is based on laptop and restaurant reviews. It involves identifying the aspects or features mentioned in a review and determining the sentiment expressed towards each aspect.
- Text Classification: This task involves classifying text into predefined categories. Sub-tasks include text-scoring, natural language inference, and semantic-similarity-scoring.
Papers
| Paper | Code | Results | Date | Stars |
|---|
Dataset Loaders
No data loaders found. You can
submit your data loader here.
No data loaders found. You can
submit your data loader here.



