PCFG SET (Probabilistic Context Free Grammar String Edit Task)
Introduced by Hupkes et al. in Compositionality decomposed: how do neural networks generalise?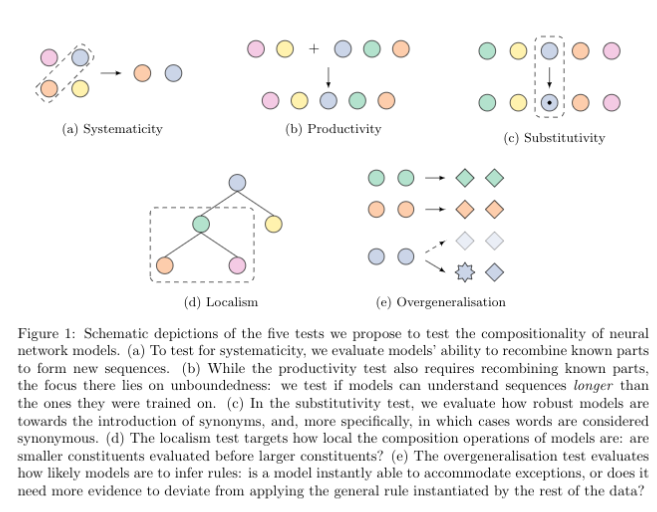
The Probabilistic Context Free Grammar String Edit Task (PCFG SET) dataset is a dataset with sequence to sequence problems specifically designed to test different aspects of compositional generalisation. In particular, the dataset contains splits to test for systematicity, productivity, substitutivity, localism and overgeneralisation.
The input alphabet of PCFG SET contains three types of words: words for unary and binary functions that represent \emph{string edit operations} (e.g. $\texttt{append}, \texttt{copy}, \texttt{reverse})$, elements to form the string sequences that these functions can be applied to (e.g. $\texttt{A}, \texttt{B}, \texttt{A1}, \texttt{B1}$), and a separator to separate the arguments of a binary function ($\texttt{,}$). The input sequences that are formed with this alphabet are sequences describing how a series of such operations are to be applied to a string argument. For instance:
- $\texttt{repeat A B C }$
- $\texttt{echo remove_first D K , E F}$
- $\texttt{append swap F G H , repeat I J}$
The input sequences are generated with a PCFG, whose production probabilities are learned with EM to match the depth and length distributions in a corpus with English sentences.
The output of a PCFG SET sequence, representing its meaning, is constructed by recursively applying the string edit operations specified in the sequence. For instance:
- $\texttt{repeat A B C }$ & $\rightarrow$ & $\texttt{A B C A B C}$
- $\texttt{echo remove_first D K , E F}$ & $\rightarrow$ & $\texttt{E F F}$
- $\texttt{append swap F G H , repeat I J}$ & $\rightarrow$ & $\texttt{H G F I J I J }$
The string alphabet used for the construction of the dataset has 520 distinct elements, the length of the string arguments to a functions is limited to 5.The dataset contains around 100 thousand examples in total. A full description of the dataset can be found in Hupkes et al (2020).
Papers
| Paper | Code | Results | Date | Stars |
|---|

