NISP (NITK-IISc Multilingual Multi-accent Speaker Profiling)
Introduced by Kalluri et al. in NISP: A Multi-lingual Multi-accent Dataset for Speaker Profiling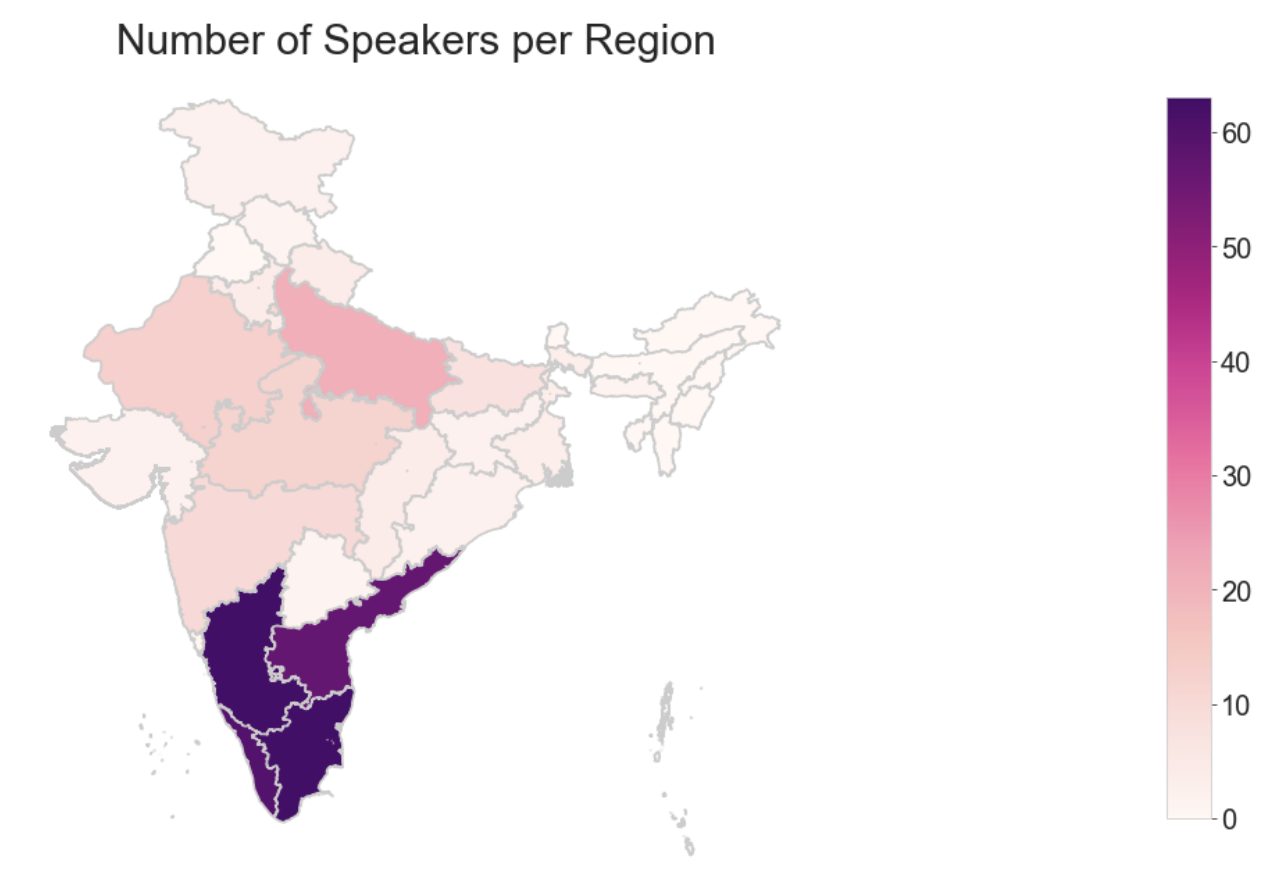
This dataset contains speech recordings along with speaker physical parameters (height, weight, shoulder size, age ) as well as regional information and linguistic information.
There are a total of 345 speakers (219 male and 126 female). The dataset contains sentences that are taken out from newspapers. Each speaker has contributed about 4-5 minutes of data that includes recordings in both English and their mother tongue. The transcript for the text is provided in UTF-8 format.
Source: NISPPapers
| Paper | Code | Results | Date | Stars |
|---|
