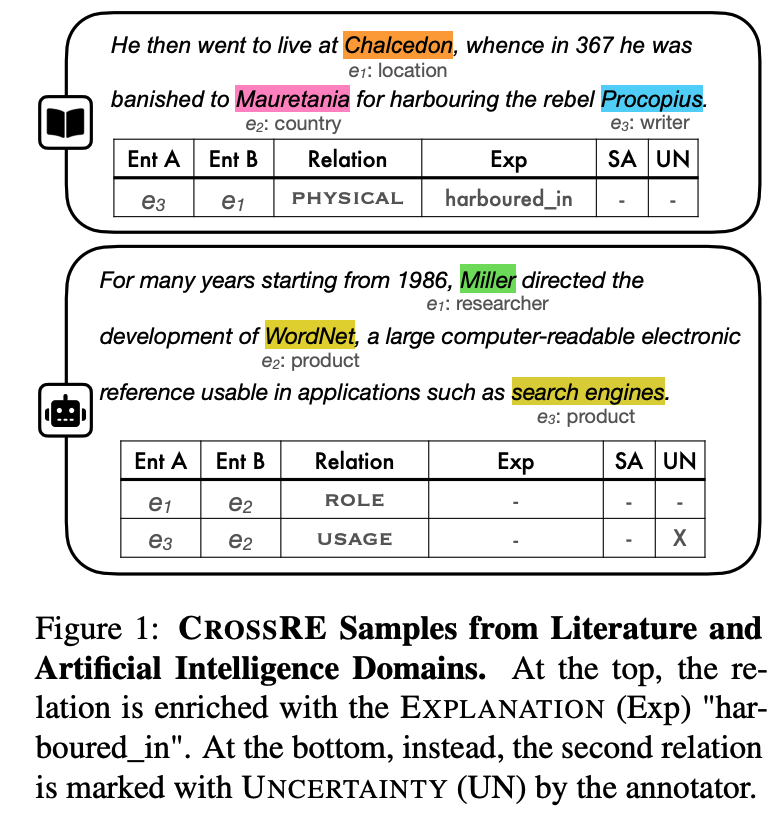
CrossRE is a cross-domain benchmark for Relation Extraction (RE), which comprises six distinct text domains and includes multi-label annotations. The dataset includes meta-data collected during annotation, to include explanations and flags of difficult instances.
Source: CrossRE: A Cross-Domain Dataset for Relation ExtractionPapers
| Paper | Code | Results | Date | Stars |
|---|
Dataset Loaders
No data loaders found. You can
submit your data loader here.
No data loaders found. You can
submit your data loader here.


