Search Results for author:
Found 115 papers, 59 papers with code
FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
However, achieving simultaneously multi-view consistency and temporal coherence while editing video sequences remains a formidable challenge.

Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Second and the remaining problem is thus 3D multiview consistency among all completed images, now guided by the seed images and their 3D proxies.
Prompt2NeRF-PIL: Fast NeRF Generation via Pretrained Implicit Latent
This paper explores promptable NeRF generation (e. g., text prompt or single image prompt) for direct conditioning and fast generation of NeRF parameters for the underlying 3D scenes, thus undoing complex intermediate steps while providing full 3D generation with conditional control.

DragVideo: Interactive Drag-style Video Editing
The main issues are: 1) how to perform direct and accurate user control in editing; 2) how to execute editings like changing shape, expression, and layout without unsightly distortion and artifacts to the edited content; and 3) how to maintain spatio-temporal consistency of video after editing.

SANeRF-HQ: Segment Anything for NeRF in High Quality
Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis.

C3Net: Compound Conditioned ControlNet for Multimodal Content Generation
Specifically, C3Net first aligns the conditions from multi-modalities to the same semantic latent space using modality-specific encoders based on contrastive training.
Stable Segment Anything Model
Thus, our solution, termed Stable-SAM, offers several advantages: 1) improved SAM's segmentation stability across a wide range of prompt qualities, while 2) retaining SAM's powerful promptable segmentation efficiency and generality, with 3) minimal learnable parameters (0. 08 M) and fast adaptation (by 1 training epoch).
Deceptive-Human: Prompt-to-NeRF 3D Human Generation with 3D-Consistent Synthetic Images
This paper presents Deceptive-Human, a novel Prompt-to-NeRF framework capitalizing state-of-the-art control diffusion models (e. g., ControlNet) to generate a high-quality controllable 3D human NeRF.
EgoPCA: A New Framework for Egocentric Hand-Object Interaction Understanding
With the surge in attention to Egocentric Hand-Object Interaction (Ego-HOI), large-scale datasets such as Ego4D and EPIC-KITCHENS have been proposed.


Scene-Generalizable Interactive Segmentation of Radiance Fields
Existing methods for interactive segmentation in radiance fields entail scene-specific optimization and thus cannot generalize across different scenes, which greatly limits their applicability.
Feature Decoupling-Recycling Network for Fast Interactive Segmentation
First, our model decouples the learning of source image semantics from the encoding of user guidance to process two types of input domains separately.
Cascade-DETR: Delving into High-Quality Universal Object Detection
While dominating on the COCO benchmark, recent Transformer-based detection methods are not competitive in diverse domains.
Segment Anything Meets Point Tracking
The Segment Anything Model (SAM) has established itself as a powerful zero-shot image segmentation model, enabled by efficient point-centric annotation and prompt-based models.
UniBoost: Unsupervised Unimodal Pre-training for Boosting Zero-shot Vision-Language Tasks
Our thorough studies validate that models pre-trained as such can learn rich representations of both modalities, improving their ability to understand how images and text relate to each other.
Segment Anything in High Quality
HQ-SAM is only trained on the introduced detaset of 44k masks, which takes only 4 hours on 8 GPUs.
 Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val
Ranked #1 on
Zero-Shot Instance Segmentation
on LVIS v1.0 val
FaceDNeRF: Semantics-Driven Face Reconstruction, Prompt Editing and Relighting with Diffusion Models
The ability to create high-quality 3D faces from a single image has become increasingly important with wide applications in video conferencing, AR/VR, and advanced video editing in movie industries.

Distill Gold from Massive Ores: Efficient Dataset Distillation via Critical Samples Selection
Our method consistently enhances the distillation algorithms, even on much larger-scale and more heterogeneous datasets, e. g. ImageNet-1K and Kinetics-400.
Deceptive-NeRF: Enhancing NeRF Reconstruction using Pseudo-Observations from Diffusion Models
We introduce Deceptive-NeRF, a novel methodology for few-shot NeRF reconstruction, which leverages diffusion models to synthesize plausible pseudo-observations to improve the reconstruction.
Registering Neural Radiance Fields as 3D Density Images
No significant work has been done to directly merge two partially overlapping scenes using NeRF representations.

Instance Neural Radiance Field
This paper presents one of the first learning-based NeRF 3D instance segmentation pipelines, dubbed as {\bf \inerflong}, or \inerf.


Mask-Free Video Instance Segmentation
A consistency loss is then enforced on the found matches.



Clean-NeRF: Reformulating NeRF to account for View-Dependent Observations
This paper analyzes the NeRF's struggles in such settings and proposes Clean-NeRF for accurate 3D reconstruction and novel view rendering in complex scenes.
Ultrahigh Resolution Image/Video Matting With Spatio-Temporal Sparsity
Instead, our method resorts to spatial and temporal sparsity for solving general UHR matting.


Compression-Aware Video Super-Resolution
Videos stored on mobile devices or delivered on the Internet are usually in compressed format and are of various unknown compression parameters, but most video super-resolution (VSR) methods often assume ideal inputs resulting in large performance gap between experimental settings and real-world applications.
ONeRF: Unsupervised 3D Object Segmentation from Multiple Views
We present ONeRF, a method that automatically segments and reconstructs object instances in 3D from multi-view RGB images without any additional manual annotations.
FLNeRF: 3D Facial Landmarks Estimation in Neural Radiance Fields
This paper presents the first significant work on directly predicting 3D face landmarks on neural radiance fields (NeRFs).
NeRF-RPN: A general framework for object detection in NeRFs
This paper presents the first significant object detection framework, NeRF-RPN, which directly operates on NeRF.

H-VFI: Hierarchical Frame Interpolation for Videos with Large Motions
The learnt deformable kernel is then utilized in convolving the input frames for predicting the interpolated frame.
Normalization Perturbation: A Simple Domain Generalization Method for Real-World Domain Shifts
Thus, we propose to perturb the channel statistics of source domain features to synthesize various latent styles, so that the trained deep model can perceive diverse potential domains and generalizes well even without observations of target domain data in training.

SDRTV-to-HDRTV Conversion via Spatial-Temporal Feature Fusion
To evaluate the performance of the proposed method, we construct a corresponding multi-frame dataset using HDR video of the HDR10 standard to conduct a comprehensive evaluation of different methods.
Scene Text Image Super-Resolution via Content Perceptual Loss and Criss-Cross Transformer Blocks
The CP Loss supervises the text reconstruction with content semantics by multi-scale text recognition features, which effectively incorporates content awareness into the framework.

Unsupervised Multi-View Object Segmentation Using Radiance Field Propagation
The core of our method is a novel propagation strategy for individual objects' radiance fields with a bidirectional photometric loss, enabling an unsupervised partitioning of a scene into salient or meaningful regions corresponding to different object instances.
DeViT: Deformed Vision Transformers in Video Inpainting
This paper proposes a novel video inpainting method.

Occlusion-Aware Instance Segmentation via BiLayer Network Architectures
Unlike previous instance segmentation methods, we model image formation as a composition of two overlapping layers, and propose Bilayer Convolutional Network (BCNet), where the top layer detects occluding objects (occluders) and the bottom layer infers partially occluded instances (occludees).
Video Mask Transfiner for High-Quality Video Instance Segmentation
While Video Instance Segmentation (VIS) has seen rapid progress, current approaches struggle to predict high-quality masks with accurate boundary details.
 Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS
Ranked #1 on
Video Instance Segmentation
on HQ-YTVIS
Self-Support Few-Shot Semantic Segmentation
Motivated by the simple Gestalt principle that pixels belonging to the same object are more similar than those to different objects of same class, we propose a novel self-support matching strategy to alleviate this problem, which uses query prototypes to match query features, where the query prototypes are collected from high-confidence query predictions.
 Ranked #12 on
Few-Shot Semantic Segmentation
on PASCAL-5i (5-Shot)
Ranked #12 on
Few-Shot Semantic Segmentation
on PASCAL-5i (5-Shot)

Learning Sequence Representations by Non-local Recurrent Neural Memory
The key challenge of sequence representation learning is to capture the long-range temporal dependencies.

GCoNet+: A Stronger Group Collaborative Co-Salient Object Detector
In this paper, we present a novel end-to-end group collaborative learning network, termed GCoNet+, which can effectively and efficiently (250 fps) identify co-salient objects in natural scenes.
 Ranked #1 on
Co-Salient Object Detection
on CoCA
Ranked #1 on
Co-Salient Object Detection
on CoCA

Human Instance Matting via Mutual Guidance and Multi-Instance Refinement
A new instance matting metric called instance matting quality (IMQ) is proposed, which addresses the absence of a unified and fair means of evaluation emphasizing both instance recognition and matting quality.
Interactiveness Field in Human-Object Interactions
Human-Object Interaction (HOI) detection plays a core role in activity understanding.
Look Back and Forth: Video Super-Resolution with Explicit Temporal Difference Modeling
Instead of directly feeding consecutive frames into a VSR model, we propose to compute the temporal difference between frames and divide those pixels into two subsets according to the level of difference.
HAA4D: Few-Shot Human Atomic Action Recognition via 3D Spatio-Temporal Skeletal Alignment
All training and testing 3D skeletons in HAA4D are globally aligned, using a deep alignment model to the same global space, making each skeleton face the negative z-direction.
Transcoded Video Restoration by Temporal Spatial Auxiliary Network
In most video platforms, such as Youtube, and TikTok, the played videos usually have undergone multiple video encodings such as hardware encoding by recording devices, software encoding by video editing apps, and single/multiple video transcoding by video application servers.
NeRF-SR: High-Quality Neural Radiance Fields using Supersampling
We present NeRF-SR, a solution for high-resolution (HR) novel view synthesis with mostly low-resolution (LR) inputs.
Mask Transfiner for High-Quality Instance Segmentation
Instead of operating on regular dense tensors, our Mask Transfiner decomposes and represents the image regions as a quadtree.
 Ranked #1 on
Instance Segmentation
on BDD100K val
Ranked #1 on
Instance Segmentation
on BDD100K val
Occlusion-Aware Video Object Inpainting
To facilitate this new research, we construct the first large-scale video object inpainting benchmark YouTube-VOI to provide realistic occlusion scenarios with both occluded and visible object masks available.
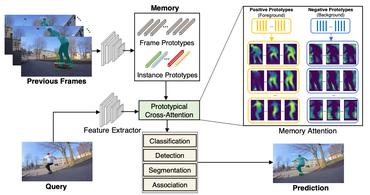
Prototypical Cross-Attention Networks for Multiple Object Tracking and Segmentation
We propose Prototypical Cross-Attention Network (PCAN), capable of leveraging rich spatio-temporal information for online multiple object tracking and segmentation.
 Ranked #1 on
Video Instance Segmentation
on BDD100K val
Ranked #1 on
Video Instance Segmentation
on BDD100K val
 Multi-Object Tracking and Segmentation
Multi-Object Tracking and Segmentation
 Multiple Object Track and Segmentation
+3
Multiple Object Track and Segmentation
+3
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
This paper presents a simple yet effective approach to modeling space-time correspondences in the context of video object segmentation.
 Ranked #7 on
Video Object Segmentation
on YouTube-VOS 2019
Ranked #7 on
Video Object Segmentation
on YouTube-VOS 2019
 Semantic Segmentation
Semantic Segmentation
 Semi-Supervised Video Object Segmentation
+1
Semi-Supervised Video Object Segmentation
+1
Few-Shot Video Object Detection
We introduce Few-Shot Video Object Detection (FSVOD) with three contributions to real-world visual learning challenge in our highly diverse and dynamic world: 1) a large-scale video dataset FSVOD-500 comprising of 500 classes with class-balanced videos in each category for few-shot learning; 2) a novel Tube Proposal Network (TPN) to generate high-quality video tube proposals for aggregating feature representation for the target video object which can be highly dynamic; 3) a strategically improved Temporal Matching Network (TMN+) for matching representative query tube features with better discriminative ability thus achieving higher diversity.
Deep Video Matting via Spatio-Temporal Alignment and Aggregation
Despite the significant progress made by deep learning in natural image matting, there has been so far no representative work on deep learning for video matting due to the inherent technical challenges in reasoning temporal domain and lack of large-scale video matting datasets.
Few-Shot Model Adaptation for Customized Facial Landmark Detection, Segmentation, Stylization and Shadow Removal
Thus, there is always a great demand in customized data annotations.

Semantic Image Matting
Specifically, we consider and learn 20 classes of matting patterns, and propose to extend the conventional trimap to semantic trimap.

Deep Occlusion-Aware Instance Segmentation with Overlapping BiLayers
Segmenting highly-overlapping objects is challenging, because typically no distinction is made between real object contours and occlusion boundaries.
 Ranked #1 on
Instance Segmentation
on KINS
Ranked #1 on
Instance Segmentation
on KINS
Group Collaborative Learning for Co-Salient Object Detection
We present a novel group collaborative learning framework (GCoNet) capable of detecting co-salient objects in real time (16ms), by simultaneously mining consensus representations at group level based on the two necessary criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module; 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module conditioning the inconsistent consensus.
Ranked #5 on
Co-Salient Object Detection
on CoCA
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance.
 Ranked #1 on
Interactive Video Object Segmentation
on DAVIS 2017
(using extra training data)
Ranked #1 on
Interactive Video Object Segmentation
on DAVIS 2017
(using extra training data)
 Interactive Video Object Segmentation
Semantic Segmentation
+2
Interactive Video Object Segmentation
Semantic Segmentation
+2
PRIN/SPRIN: On Extracting Point-wise Rotation Invariant Features
Spherical Voxel Convolution and Point Re-sampling are proposed to extract rotation invariant features for each point.

Semi-Supervised Few-Shot Atomic Action Recognition
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling.
HAA500: Human-Centric Atomic Action Dataset with Curated Videos
We contribute HAA500, a manually annotated human-centric atomic action dataset for action recognition on 500 classes with over 591K labeled frames.
 Ranked #1 on
Action Recognition
on HAA500
Ranked #1 on
Action Recognition
on HAA500

Pose-Guided High-Resolution Appearance Transfer via Progressive Training
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person.
GSNet: Joint Vehicle Pose and Shape Reconstruction with Geometrical and Scene-aware Supervision
GSNet utilizes a unique four-way feature extraction and fusion scheme and directly regresses 6DoF poses and shapes in a single forward pass.
 Ranked #1 on
Autonomous Driving
on ApolloCar3D
Ranked #1 on
Autonomous Driving
on ApolloCar3D


Commonality-Parsing Network across Shape and Appearance for Partially Supervised Instance Segmentation
We propose to learn the underlying class-agnostic commonalities that can be generalized from mask-annotated categories to novel categories.
 Ranked #79 on
Instance Segmentation
on COCO test-dev
Ranked #79 on
Instance Segmentation
on COCO test-dev
Fully Convolutional Networks for Continuous Sign Language Recognition
Continuous sign language recognition (SLR) is a challenging task that requires learning on both spatial and temporal dimensions of signing frame sequences.

Dense Hybrid Recurrent Multi-view Stereo Net with Dynamic Consistency Checking
In this paper, we propose an efficient and effective dense hybrid recurrent multi-view stereo net with dynamic consistency checking, namely $D^{2}$HC-RMVSNet, for accurate dense point cloud reconstruction.
Dive Deeper Into Box for Object Detection
Anchor free methods have defined the new frontier in state-of-the-art object detection researches where accurate bounding box estimation is the key to the success of these methods.
Fast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
Significant progress has been made in Video Object Segmentation (VOS), the video object tracking task in its finest level.
![]() Ranked #71 on
Semi-Supervised Video Object Segmentation
on DAVIS 2016
Ranked #71 on
Semi-Supervised Video Object Segmentation
on DAVIS 2016

Cascaded deep monocular 3D human pose estimation with evolutionary training data
End-to-end deep representation learning has achieved remarkable accuracy for monocular 3D human pose estimation, yet these models may fail for unseen poses with limited and fixed training data.
 Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
Ranked #13 on
Weakly-supervised 3D Human Pose Estimation
on Human3.6M
One-Shot Object Detection without Fine-Tuning
Deep learning has revolutionized object detection thanks to large-scale datasets, but their object categories are still arguably very limited.

CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
In this paper, we propose a novel approach to address the high-resolution segmentation problem without using any high-resolution training data.
 Ranked #1 on
Semantic Segmentation
on BIG
(using extra training data)
Ranked #1 on
Semantic Segmentation
on BIG
(using extra training data)
Learning Video Object Segmentation from Unlabeled Videos
We propose a new method for video object segmentation (VOS) that addresses object pattern learning from unlabeled videos, unlike most existing methods which rely heavily on extensive annotated data.

Spatial-Scale Aligned Network for Fine-Grained Recognition
Existing approaches for fine-grained visual recognition focus on learning marginal region-based representations while neglecting the spatial and scale misalignments, leading to inferior performance.
Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
n this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net with self-adaptive view aggregation for accurate and complete dense point cloud reconstruction.

Reflective Decoding Network for Image Captioning
State-of-the-art image captioning methods mostly focus on improving visual features, less attention has been paid to utilizing the inherent properties of language to boost captioning performance.
 Ranked #4 on
Image Captioning
on MS COCO
Ranked #4 on
Image Captioning
on MS COCO

Push for Center Learning via Orthogonalization and Subspace Masking for Person Re-Identification
Person re-identification aims to identify whether pairs of images belong to the same person or not.

Non-local Recurrent Neural Memory for Supervised Sequence Modeling
Typical methods for supervised sequence modeling are built upon the recurrent neural networks to capture temporal dependencies.

Cross-Domain Adaptation for Animal Pose Estimation
Therefore, the easily available human pose dataset, which is of a much larger scale than our labeled animal dataset, provides important prior knowledge to boost up the performance on animal pose estimation.


Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
To train our network, we contribute a new dataset that contains 1000 categories of various objects with high-quality annotations.
 Ranked #21 on
Few-Shot Object Detection
on MS-COCO (10-shot)
Ranked #21 on
Few-Shot Object Detection
on MS-COCO (10-shot)

SF-Net: Structured Feature Network for Continuous Sign Language Recognition
The proposed SF-Net extracts features in a structured manner and gradually encodes information at the frame level, the gloss level and the sentence level into the feature representation.
DAWN: Dual Augmented Memory Network for Unsupervised Video Object Tracking
Our Dual Augmented Memory Network (DAWN) is unique in remembering both target and background, and using an improved attention LSTM memory to guide the focus on memorized features.
FSS-1000: A 1000-Class Dataset for Few-Shot Segmentation
In this paper, we are interested in few-shot object segmentation where the number of annotated training examples are limited to 5 only.
 Ranked #20 on
Few-Shot Semantic Segmentation
on FSS-1000 (5-shot)
Ranked #20 on
Few-Shot Semantic Segmentation
on FSS-1000 (5-shot)
StableNet: Semi-Online, Multi-Scale Deep Video Stabilization
Video stabilization algorithms are of greater importance nowadays with the prevalence of hand-held devices which unavoidably produce videos with undesirable shaky motions.
Landmark Assisted CycleGAN for Cartoon Face Generation
In this paper, we are interested in generating an cartoon face of a person by using unpaired training data between real faces and cartoon ones.

Memory-Attended Recurrent Network for Video Captioning
Typical techniques for video captioning follow the encoder-decoder framework, which can only focus on one source video being processed.
LADN: Local Adversarial Disentangling Network for Facial Makeup and De-Makeup
Central to our method are multiple and overlapping local adversarial discriminators in a content-style disentangling network for achieving local detail transfer between facial images, with the use of asymmetric loss functions for dramatic makeup styles with high-frequency details.

Pointwise Rotation-Invariant Network with Adaptive Sampling and 3D Spherical Voxel Convolution
Point cloud analysis without pose priors is very challenging in real applications, as the orientations of point clouds are often unknown.
Physics-Based Generative Adversarial Models for Image Restoration and Beyond
We present an algorithm to directly solve numerous image restoration problems (e. g., image deblurring, image dehazing, image deraining, etc.).

Pairwise Body-Part Attention for Recognizing Human-Object Interactions
We propose a new pairwise body-part attention model which can learn to focus on crucial parts, and their correlations for HOI recognition.
 Ranked #5 on
Human-Object Interaction Detection
on HICO
Ranked #5 on
Human-Object Interaction Detection
on HICO
Learning Dual Convolutional Neural Networks for Low-Level Vision
These problems usually involve the estimation of two components of the target signals: structures and details.

Weakly and Semi Supervised Human Body Part Parsing via Pose-Guided Knowledge Transfer
In this paper, we present a novel method to generate synthetic human part segmentation data using easily-obtained human keypoint annotations.
 Ranked #4 on
Human Part Segmentation
on PASCAL-Part
(using extra training data)
Ranked #4 on
Human Part Segmentation
on PASCAL-Part
(using extra training data)

MAVOT: Memory-Augmented Video Object Tracking
We introduce a one-shot learning approach for video object tracking.
Deep High Dynamic Range Imaging with Large Foreground Motions
In state-of-the-art deep HDR imaging, input images are first aligned using optical flows before merging, which are still error-prone due to occlusion and large motions.
Image Generation from Sketch Constraint Using Contextual GAN
We train a generated adversarial network, i. e, contextual GAN to learn the joint distribution of sketch and the corresponding image by using joint images.

Deep Video Generation, Prediction and Completion of Human Action Sequences
In the second stage, a skeleton-to-image network is trained, which is used to generate a human action video given the complete human pose sequence generated in the first stage.
 Ranked #5 on
Human action generation
on NTU RGB+D 2D
Ranked #5 on
Human action generation
on NTU RGB+D 2D

Adversarial Attacks Beyond the Image Space
Though image-space adversaries can be interpreted as per-pixel albedo change, we verify that they cannot be well explained along these physically meaningful dimensions, which often have a non-local effect.

Learning Discriminative Data Fitting Functions for Blind Image Deblurring
Solving blind image deblurring usually requires defining a data fitting function and image priors.
Image Dehazing using Bilinear Composition Loss Function
In this paper, we introduce a bilinear composition loss function to address the problem of image dehazing.

Weakly- and Self-Supervised Learning for Content-Aware Deep Image Retargeting
Our method implicitly learns an attention map, which leads to a content-aware shift map for image retargeting.

Attribute-Guided Face Generation Using Conditional CycleGAN
We are interested in attribute-guided face generation: given a low-res face input image, an attribute vector that can be extracted from a high-res image (attribute image), our new method generates a high-res face image for the low-res input that satisfies the given attributes.
A Unified Approach of Multi-scale Deep and Hand-crafted Features for Defocus Estimation
In this paper, we introduce robust and synergetic hand-crafted features and a simple but efficient deep feature from a convolutional neural network (CNN) architecture for defocus estimation.
 Ranked #2 on
Defocus Estimation
on CUHK - Blur Detection Dataset
Ranked #2 on
Defocus Estimation
on CUHK - Blur Detection Dataset

Accurate Single Stage Detector Using Recurrent Rolling Convolution
In this paper, we proposed a novel single stage end-to-end trainable object detection network to overcome this limitation.

RMPE: Regional Multi-person Pose Estimation
In this paper, we propose a novel regional multi-person pose estimation (RMPE) framework to facilitate pose estimation in the presence of inaccurate human bounding boxes.
 Ranked #1 on
Pose Estimation
on UAV-Human
Ranked #1 on
Pose Estimation
on UAV-Human
Refining Geometry from Depth Sensors using IR Shading Images
To resolve the ambiguity in our model between the normals and distances, we utilize an initial 3D mesh from the Kinect fusion and multi-view information to reliably estimate surface details that were not captured and reconstructed by the Kinect fusion.
Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures
We alternate the pruning and retraining to further reduce zero activations in a network.
Efficient and Robust Color Consistency for Community Photo Collections
We present a robust low-rank matrix factorization method to estimate the unknown parameters of this model.
Deep Saliency with Encoded Low level Distance Map and High Level Features
Recent advances in saliency detection have utilized deep learning to obtain high level features to detect salient regions in a scene.
Look, Listen and Learn - A Multimodal LSTM for Speaker Identification
This task not only requires collective perception over both visual and auditory signals, the robustness to handle severe quality degradations and unconstrained content variations are also indispensable.
RGB-Guided Hyperspectral Image Upsampling
On the contrary, latest imaging sensors capture a RGB image with resolution of multiple times larger than a hyperspectral image.
Fast Randomized Singular Value Thresholding for Low-rank Optimization
The problems related to NNM, or WNNM, can be solved iteratively by applying a closed-form proximal operator, called Singular Value Thresholding (SVT), or Weighted SVT, but they suffer from high computational cost of Singular Value Decomposition (SVD) at each iteration.

Fast Randomized Singular Value Thresholding for Nuclear Norm Minimization
The problems related to NNM (or WNNM) can be solved iteratively by applying a closed-form proximal operator, called Singular Value Thresholding (SVT) (or Weighted SVT), but they suffer from high computational cost to compute a Singular Value Decomposition (SVD) at each iteration.
Data-Driven Depth Map Refinement via Multi-Scale Sparse Representation
Depth maps captured by consumer-level depth cameras such as Kinect are usually degraded by noise, missing values, and quantization.
Accurate Depth Map Estimation From a Lenslet Light Field Camera
This paper introduces an algorithm that accurately estimates depth maps using a lenslet light field camera.
Partial Sum Minimization of Singular Values in Robust PCA: Algorithm and Applications
Robust Principal Component Analysis (RPCA) via rank minimization is a powerful tool for recovering underlying low-rank structure of clean data corrupted with sparse noise/outliers.

Salient Region Detection via High-Dimensional Color Transform
By mapping a low dimensional RGB color to a feature vector in a high-dimensional color space, we show that we can linearly separate the salient regions from the background by finding an optimal linear combination of color coefficients in the high-dimensional color space.
Calibrating a Non-isotropic Near Point Light Source using a Plane
We show that a non-isotropic near point light source rigidly attached to a camera can be calibrated using multiple images of a weakly textured planar scene.
Exploiting Shading Cues in Kinect IR Images for Geometry Refinement
To resolve ambiguity in our model between normals and distance, we utilize an initial 3D mesh from the Kinect fusion and multi-view information to reliably estimate surface details that were not reconstructed by the Kinect fusion.
Shading-Based Shape Refinement of RGB-D Images
We present a shading-based shape refinement algorithm which uses a noisy, incomplete depth map from Kinect to help resolve ambiguities in shape-from-shading.
