Search Results for author:
Found 68 papers, 32 papers with code
Explanations of Classifiers Enhance Medical Image Segmentation via End-to-end Pre-training
Based on a large-scale medical image classification dataset, our work collects explanations from well-trained classifiers to generate pseudo labels of segmentation tasks.


DreamInpainter: Text-Guided Subject-Driven Image Inpainting with Diffusion Models
Our extensive experiments demonstrate the superior performance of our method in terms of visual quality, identity preservation, and text control, showcasing its effectiveness in the context of text-guided subject-driven image inpainting.

Towards General Purpose Vision Foundation Models for Medical Image Analysis: An Experimental Study of DINOv2 on Radiology Benchmarks
To measure the effectiveness and generalizability of DINOv2's feature representations, we analyze the model across medical image analysis tasks including disease classification and organ segmentation on both 2D and 3D images, and under different settings like kNN, few-shot learning, linear-probing, end-to-end fine-tuning, and parameter-efficient fine-tuning.
MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
The deployment of large-scale text-to-image diffusion models on mobile devices is impeded by their substantial model size and slow inference speed.

UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge.
Polar-Net: A Clinical-Friendly Model for Alzheimer's Disease Detection in OCTA Images
Optical Coherence Tomography Angiography (OCTA) is a promising tool for detecting Alzheimer's disease (AD) by imaging the retinal microvasculature.
CUPre: Cross-domain Unsupervised Pre-training for Few-Shot Cell Segmentation
While pre-training on object detection tasks, such as Common Objects in Contexts (COCO) [1], could significantly boost the performance of cell segmentation, it still consumes on massive fine-annotated cell images [2] with bounding boxes, masks, and cell types for every cell in every image, to fine-tune the pre-trained model.

MedSyn: Text-guided Anatomy-aware Synthesis of High-Fidelity 3D CT Images
This study focuses on two main objectives: (1) the development of a method for creating images based on textual prompts and anatomical components, and (2) the capability to generate new images conditioning on anatomical elements.

A Generic Fundus Image Enhancement Network Boosted by Frequency Self-supervised Representation Learning
Fundus photography is prone to suffer from image quality degradation that impacts clinical examination performed by ophthalmologists or intelligent systems.

CLIP3Dstyler: Language Guided 3D Arbitrary Neural Style Transfer
In this paper, we propose a novel language-guided 3D arbitrary neural style transfer method (CLIP3Dstyler).

PALM: Open Fundus Photograph Dataset with Pathologic Myopia Recognition and Anatomical Structure Annotation
Our databases comprises 1200 images with associated labels for the pathologic myopia category and manual annotations of the optic disc, the position of the fovea and delineations of lesions such as patchy retinal atrophy (including peripapillary atrophy) and retinal detachment.
Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation
In Med-SA, we propose Space-Depth Transpose (SD-Trans) to adapt 2D SAM to 3D medical images and Hyper-Prompting Adapter (HyP-Adpt) to achieve prompt-conditioned adaptation.

Simplifying Low-Light Image Enhancement Networks with Relative Loss Functions
In this paper, to make the learning easier in low-light image enhancement, we introduce FLW-Net (Fast and LightWeight Network) and two relative loss functions.

Vessel-Promoted OCT to OCTA Image Translation by Heuristic Contextual Constraints
In this paper, we propose a novel framework, TransPro, that translates 3D Optical Coherence Tomography (OCT) images into exclusive 3D OCTA images using an image translation pattern.
Video4MRI: An Empirical Study on Brain Magnetic Resonance Image Analytics with CNN-based Video Classification Frameworks
Due to the high similarity between MRI data and videos, we conduct extensive empirical studies on video recognition techniques for MRI classification to answer the questions: (1) can we directly use video recognition models for MRI classification, (2) which model is more appropriate for MRI, (3) are the common tricks like data augmentation in video recognition still useful for MRI classification?


MedSegDiff-V2: Diffusion based Medical Image Segmentation with Transformer
To effectively integrate these two cutting-edge techniques for the Medical image segmentation, we propose a novel Transformer-based Diffusion framework, called MedSegDiff-V2.
Unpaired Image-to-Image Translation With Shortest Path Regularization
In this paper, we start from a different perspective and consider the paths connecting the two domains.

Multi-rater Prism: Learning self-calibrated medical image segmentation from multiple raters
In this paper, we propose a novel neural network framework, called Multi-Rater Prism (MrPrism) to learn the medical image segmentation from multiple labels.
ExpNet: A unified network for Expert-Level Classification
In the paper, we call them expert-level classification.
MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
Inspired by the success of DPM, we propose the first DPM based model toward general medical image segmentation tasks, which we named MedSegDiff.


Learning to screen Glaucoma like the ophthalmologists
GAMMA Challenge is organized to encourage the AI models to screen the glaucoma from a combination of 2D fundus image and 3D optical coherence tomography volume, like the ophthalmologists.
Multi-Scale Multi-Target Domain Adaptation for Angle Closure Classification
Based on these domain-invariant features at different scales, the deep model trained on the source domain is able to classify angle closure on multiple target domains even without any annotations in these domains.

Calibrate the inter-observer segmentation uncertainty via diagnosis-first principle
Inspired by this observation, we propose diagnosis-first principle, which is to take disease diagnosis as the criterion to calibrate the inter-observer segmentation uncertainty.

Dataset and Evaluation algorithm design for GOALS Challenge
Glaucoma causes irreversible vision loss due to damage to the optic nerve, and there is no cure for glaucoma. OCT imaging modality is an essential technique for assessing glaucomatous damage since it aids in quantifying fundus structures.
Towards Lightweight Super-Resolution with Dual Regression Learning
Nevertheless, it is hard for existing model compression methods to accurately identify the redundant components due to the extremely large SR mapping space.

Adversarial Consistency for Single Domain Generalization in Medical Image Segmentation
An organ segmentation method that can generalize to unseen contrasts and scanner settings can significantly reduce the need for retraining of deep learning models.
SeATrans: Learning Segmentation-Assisted diagnosis model via Transformer
To model the segmentation-diagnosis interaction, SeA-block first embeds the diagnosis feature based on the segmentation information via the encoder, and then transfers the embedding back to the diagnosis feature space by a decoder.
Learning self-calibrated optic disc and cup segmentation from multi-rater annotations
In this paper, we propose a novel neural network framework to learn OD/OC segmentation from multi-rater annotations.
One Hyper-Initializer for All Network Architectures in Medical Image Analysis
Pre-training is essential to deep learning model performance, especially in medical image analysis tasks where limited training data are available.
Contrastive Centroid Supervision Alleviates Domain Shift in Medical Image Classification
Deep learning based medical imaging classification models usually suffer from the domain shift problem, where the classification performance drops when training data and real-world data differ in imaging equipment manufacturer, image acquisition protocol, patient populations, etc.
Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation
The first one lets T compete with G to achieve maximum perturbation.
REFUGE2 Challenge: A Treasure Trove for Multi-Dimension Analysis and Evaluation in Glaucoma Screening
Here we release a multi-annotation, multi-quality, and multi-device color fundus image dataset for glaucoma analysis on an original challenge -- Retinal Fundus Glaucoma Challenge 2nd Edition (REFUGE2).
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
The ADAM challenge consisted of four tasks which cover the main aspects of detecting and characterizing AMD from fundus images, including detection of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions.
GAMMA Challenge:Glaucoma grAding from Multi-Modality imAges
However, although numerous algorithms are proposed based on fundus images or OCT volumes in computer-aided diagnosis, there are still few methods leveraging both of the modalities for the glaucoma assessment.
Opinions Vary? Diagnosis First!
Motivated by the observation that OD/OC segmentation is often used for the glaucoma diagnosis clinically, in this paper, we propose a novel strategy to fuse the multi-rater OD/OC segmentation labels via the glaucoma diagnosis performance.
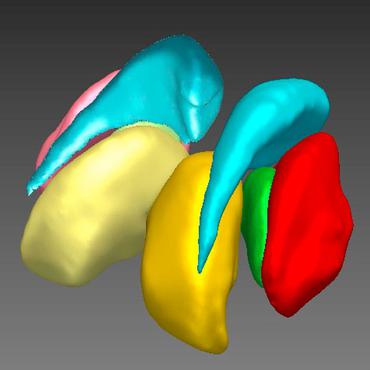
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwannoma and Cochlea Segmentation
The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137).
Unaligned Image-to-Image Translation by Learning to Reweight
An essential yet restrictive assumption for unsupervised image translation is that the two domains are aligned, e. g., for the selfie2anime task, the anime (selfie) domain must contain only anime (selfie) face images that can be translated to some images in the other domain.

Progressive Hard-case Mining across Pyramid Levels for Object Detection
Based on focal loss with ATSS-R50, our approach achieves 40. 5 AP, surpassing the state-of-the-art QFL (Quality Focal Loss, 39. 9 AP) and VFL (Varifocal Loss, 40. 1 AP).

Box-Adapt: Domain-Adaptive Medical Image Segmentation using Bounding BoxSupervision
In this paper, we propose a weakly supervised do-main adaptation setting, in which we can partially label newdatasets with bounding boxes, which are easier and cheaperto obtain than segmentation masks.
Weighing Features of Lung and Heart Regions for Thoracic Disease Classification
By zeroing features of non-lung and heart regions in attention maps, we can effectively exploit their disease-specific cues in lung and heart regions.
DSANet: Dynamic Segment Aggregation Network for Video-Level Representation Learning
Long-range and short-range temporal modeling are two complementary and crucial aspects of video recognition.
 Ranked #6 on
Action Recognition
on ActivityNet
Ranked #6 on
Action Recognition
on ActivityNet


A Multi-Branch Hybrid Transformer Networkfor Corneal Endothelial Cell Segmentation
Corneal endothelial cell segmentation plays a vital role inquantifying clinical indicators such as cell density, coefficient of variation, and hexagonality.
Probabilistic Latent Factor Model for Collaborative Filtering with Bayesian Inference
Latent Factor Model (LFM) is one of the most successful methods for Collaborative filtering (CF) in the recommendation system, in which both users and items are projected into a joint latent factor space.


Attention-based Saliency Hashing for Ophthalmic Image Retrieval
The different grades or classes of ophthalmic images may be share similar overall performance but have subtle differences that can be differentiated by mining salient regions.

Hierarchical Amortized Training for Memory-efficient High Resolution 3D GAN
During training, we adopt a hierarchical structure that simultaneously generates a low-resolution version of the image and a randomly selected sub-volume of the high-resolution image.
Robust Collaborative Learning of Patch-level and Image-level Annotations for Diabetic Retinopathy Grading from Fundus Image
As a result, it exploits more discriminative features for DR grading.
Residual-CycleGAN based Camera Adaptation for Robust Diabetic Retinopathy Screening
How can we train a classification model on labeled fundus images ac-quired from only one camera brand, yet still achieves good performance on im-ages taken by other brands of cameras?
Robust Retinal Vessel Segmentation from a Data Augmentation Perspective
In this paper, we propose two new data augmentation modules, namely, channel-wise random Gamma correction and channel-wise random vessel augmentation.

Retinal Image Segmentation with a Structure-Texture Demixing Network
Retinal image segmentation plays an important role in automatic disease diagnosis.
Reconstruction and Quantification of 3D Iris Surface for Angle-Closure Glaucoma Detection in Anterior Segment OCT
We consider it to be the first work to detect angle-closure glaucoma by means of 3D representation.
Open-Narrow-Synechiae Anterior Chamber Angle Classification in AS-OCT Sequences
However, clinical diagnosis requires a more discriminating ACA three-class system (i. e., open, narrow, or synechiae angles) for the benefit of clinicians who seek better to understand the progression of the spectrum of angle-closure glaucoma types.

AGE Challenge: Angle Closure Glaucoma Evaluation in Anterior Segment Optical Coherence Tomography
To address this, we organized the Angle closure Glaucoma Evaluation challenge (AGE), held in conjunction with MICCAI 2019.
A Thorough Comparison Study on Adversarial Attacks and Defenses for Common Thorax Disease Classification in Chest X-rays
In this paper, we aim to review various adversarial attack and defense methods on chest X-rays.
Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution
Extensive experiments with paired training data and unpaired real-world data demonstrate our superiority over existing methods.
Twin Auxilary Classifiers GAN
One of the popular conditional models is Auxiliary Classifier GAN (AC-GAN) that generates highly discriminative images by extending the loss function of GAN with an auxiliary classifier.
 Ranked #2 on
Image Generation
on CIFAR-100
Ranked #2 on
Image Generation
on CIFAR-100

REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one.
Attention Guided Network for Retinal Image Segmentation
Learning structural information is critical for producing an ideal result in retinal image segmentation.
Evaluation of Retinal Image Quality Assessment Networks in Different Color-spaces
Retinal image quality assessment (RIQA) is essential for controlling the quality of retinal imaging and guaranteeing the reliability of diagnoses by ophthalmologists or automated analysis systems.
Twin Auxiliary Classifiers GAN
One of the popular conditional models is Auxiliary Classifier GAN (AC-GAN), which generates highly discriminative images by extending the loss function of GAN with an auxiliary classifier.
 Ranked #2 on
Conditional Image Generation
on CIFAR-100
Ranked #2 on
Conditional Image Generation
on CIFAR-100
Generative-Discriminative Complementary Learning
The success of such approaches heavily depends on high-quality labeled instances, which are not easy to obtain, especially as the number of candidate classes increases.
You Only Look & Listen Once: Towards Fast and Accurate Visual Grounding
Most state-of-the-art methods in VG operate in a two-stage manner, wherein the first stage an object detector is adopted to generate a set of object proposals from the input image and the second stage is simply formulated as a cross-modal matching problem that finds the best match between the language query and all region proposals.
Angle-Closure Detection in Anterior Segment OCT based on Multi-Level Deep Network
A Multi-Level Deep Network (MLDN) is proposed to formulate this learning, which utilizes three particular AS-OCT regions based on clinical priors: the global anterior segment structure, local iris region, and anterior chamber angle (ACA) patch.
Robust Angular Local Descriptor Learning
In recent years, the learned local descriptors have outperformed handcrafted ones by a large margin, due to the powerful deep convolutional neural network architectures such as L2-Net [1] and triplet based metric learning [2].

Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge
This study assesses the state-of-the-art machine learning (ML) methods used for brain tumor image analysis in mpMRI scans, during the last seven instances of the International Brain Tumor Segmentation (BraTS) challenge, i. e., 2012-2018.
Dual Reconstruction Nets for Image Super-Resolution with Gradient Sensitive Loss
However, most deep learning methods employ feed-forward architectures, and thus the dependencies between LR and HR images are not fully exploited, leading to limited learning performance.
Multi-Context Deep Network for Angle-Closure Glaucoma Screening in Anterior Segment OCT
A major cause of irreversible visual impairment is angle-closure glaucoma, which can be screened through imagery from Anterior Segment Optical Coherence Tomography (AS-OCT).
Disc-aware Ensemble Network for Glaucoma Screening from Fundus Image
Specifically, a novel Disc-aware Ensemble Network (DENet) for automatic glaucoma screening is proposed, which integrates the deep hierarchical context of the global fundus image and the local optic disc region.
Joint Optic Disc and Cup Segmentation Based on Multi-label Deep Network and Polar Transformation
The proposed M-Net mainly consists of multi-scale input layer, U-shape convolutional network, side-output layer, and multi-label loss function.
 Ranked #4 on
Optic Disc Segmentation
on REFUGE
Ranked #4 on
Optic Disc Segmentation
on REFUGE
