Search Results for author:
Found 100 papers, 40 papers with code
S2DNet: Learning Image Features for Accurate Sparse-to-Dense Matching
Establishing robust and accurate correspondences is a fundamental backbone to many computer vision algorithms.

PyTorchGeoNodes: Enabling Differentiable Shape Programs for 3D Shape Reconstruction
In our experiments, we apply our algorithm to reconstruct 3D objects in the ScanNet dataset and evaluate our results against CAD model retrieval-based reconstructions.


Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
We propose Gaussian Frosting, a novel mesh-based representation for high-quality rendering and editing of complex 3D effects in real-time.
BOP Challenge 2023 on Detection, Segmentation and Pose Estimation of Seen and Unseen Rigid Objects
In the new tasks, methods were required to learn new objects during a short onboarding stage (max 5 minutes, 1 GPU) from provided 3D object models.

Correspondences of the Third Kind: Camera Pose Estimation from Object Reflection
In this paper, we introduce correspondences of the third kind we call reflection correspondences and show that they can help estimate camera pose by just looking at objects without relying on the background.
GigaPose: Fast and Robust Novel Object Pose Estimation via One Correspondence
We present GigaPose, a fast, robust, and accurate method for CAD-based novel object pose estimation in RGB images.

SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering
It is however challenging to extract a mesh from the millions of tiny 3D gaussians as these gaussians tend to be unorganized after optimization and no method has been proposed so far.
BEVContrast: Self-Supervision in BEV Space for Automotive Lidar Point Clouds
We present a surprisingly simple and efficient method for self-supervision of 3D backbone on automotive Lidar point clouds.

HOC-Search: Efficient CAD Model and Pose Retrieval from RGB-D Scans
We present an automated and efficient approach for retrieving high-quality CAD models of objects and their poses in a scene captured by a moving RGB-D camera.


CNOS: A Strong Baseline for CAD-based Novel Object Segmentation
We propose a simple three-stage approach to segment unseen objects in RGB images using their CAD models.
You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds.

NOPE: Novel Object Pose Estimation from a Single Image
The practicality of 3D object pose estimation remains limited for many applications due to the need for prior knowledge of a 3D model and a training period for new objects.
MACARONS: Mapping And Coverage Anticipation with RGB Online Self-Supervision
We introduce a method that simultaneously learns to explore new large environments and to reconstruct them in 3D from color images only.
Automatically Annotating Indoor Images with CAD Models via RGB-D Scans
We present an automatic method for annotating images of indoor scenes with the CAD models of the objects by relying on RGB-D scans.
In-Hand 3D Object Scanning from an RGB Sequence
As direct optimization over all shape and pose parameters is prone to fail without coarse-level initialization, we propose an incremental approach that starts by splitting the sequence into carefully selected overlapping segments within which the optimization is likely to succeed.
Long-Lived Accurate Keypoints in Event Streams
Since this integration is required, we claim it is better to predict the keypoints' trajectories for the time period rather than single locations, as done in previous approaches.

A Simple and Powerful Global Optimization for Unsupervised Video Object Segmentation
We propose a simple, yet powerful approach for unsupervised object segmentation in videos.
 Ranked #1 on
Unsupervised Video Object Segmentation
on SegTrack v2
(Jaccard (Mean) metric)
Ranked #1 on
Unsupervised Video Object Segmentation
on SegTrack v2
(Jaccard (Mean) metric)

PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data).
SCONE: Surface Coverage Optimization in Unknown Environments by Volumetric Integration
Our method scales to large scenes and handles free camera motion: It takes as input an arbitrarily large point cloud gathered by a depth sensor as well as camera poses to predict NBV.
MonteBoxFinder: Detecting and Filtering Primitives to Fit a Noisy Point Cloud
We present MonteBoxFinder, a method that, given a noisy input point cloud, fits cuboids to the input scene.
MCTS with Refinement for Proposals Selection Games in Scene Understanding
We also introduce a novel differentiable method for rendering the polygonal shapes of these proposals.
Back to MLP: A Simple Baseline for Human Motion Prediction
This paper tackles the problem of human motion prediction, consisting in forecasting future body poses from historically observed sequences.


Templates for 3D Object Pose Estimation Revisited: Generalization to New Objects and Robustness to Occlusions
It relies on a small set of training objects to learn local object representations, which allow us to locally match the input image to a set of "templates", rendered images of the CAD models for the new objects.

UVO Challenge on Video-based Open-World Segmentation 2021: 1st Place Solution
In this report, we introduce our (pretty straightforard) two-step "detect-then-match" video instance segmentation method.


1st Place Solution for the UVO Challenge on Image-based Open-World Segmentation 2021
We describe our two-stage instance segmentation framework we use to compete in the challenge.
HO-3D_v3: Improving the Accuracy of Hand-Object Annotations of the HO-3D Dataset
HO-3D is a dataset providing image sequences of various hand-object interaction scenarios annotated with the 3D pose of the hand and the object and was originally introduced as HO-3D_v2.
Visual Correspondence Hallucination
Given a pair of partially overlapping source and target images and a keypoint in the source image, the keypoint's correspondent in the target image can be either visible, occluded or outside the field of view.
Single Image Depth Prediction with Wavelet Decomposition
We present a novel method for predicting accurate depths from monocular images with high efficiency.

Keypoint Transformer: Solving Joint Identification in Challenging Hands and Object Interactions for Accurate 3D Pose Estimation
We propose a robust and accurate method for estimating the 3D poses of two hands in close interaction from a single color image.
 Ranked #4 on
hand-object pose
on HO-3D
Ranked #4 on
hand-object pose
on HO-3D

Learning to Better Segment Objects from Unseen Classes with Unlabeled Videos
Through extensive experiments, we show that our method can generate a high-quality training set which significantly boosts the performance of segmenting objects of unseen classes.
MonteFloor: Extending MCTS for Reconstructing Accurate Large-Scale Floor Plans
For this step, we propose a novel differentiable method for rendering the polygonal shapes of these proposals.
Back to the Feature: Learning Robust Camera Localization from Pixels to Pose
In this paper, we go Back to the Feature: we argue that deep networks should focus on learning robust and invariant visual features, while the geometric estimation should be left to principled algorithms.

Monte Carlo Scene Search for 3D Scene Understanding
We explore how a general AI algorithm can be used for 3D scene understanding to reduce the need for training data.
Neural Reprojection Error: Merging Feature Learning and Camera Pose Estimation
Absolute camera pose estimation is usually addressed by sequentially solving two distinct subproblems: First a feature matching problem that seeks to establish putative 2D-3D correspondences, and then a Perspective-n-Point problem that minimizes, with respect to the camera pose, the sum of so-called Reprojection Errors (RE).
3D Object Detection and Pose Estimation of Unseen Objects in Color Images with Local Surface Embeddings
We demonstrate the performance of this approach on the T-LESS dataset, by using a small number of objects to learn the embedding and testing it on the other objects.

Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild
In this paper, we tackle the problems of few-shot object detection and few-shot viewpoint estimation.
 Ranked #14 on
Few-Shot Object Detection
on MS-COCO (30-shot)
Ranked #14 on
Few-Shot Object Detection
on MS-COCO (30-shot)


Geometric Correspondence Fields: Learned Differentiable Rendering for 3D Pose Refinement in the Wild
We present a novel 3D pose refinement approach based on differentiable rendering for objects of arbitrary categories in the wild.
Recent Advances in 3D Object and Hand Pose Estimation
3D object and hand pose estimation have huge potentials for Augmented Reality, to enable tangible interfaces, natural interfaces, and blurring the boundaries between the real and virtual worlds.

ALCN: Adaptive Local Contrast Normalization
We show that our method significantly outperforms standard normalization methods and would also be appear to be universal since it does not have to be re-trained for each new application.

S2DNet: Learning Accurate Correspondences for Sparse-to-Dense Feature Matching
Establishing robust and accurate correspondences is a fundamental backbone to many computer vision algorithms.
Measuring Generalisation to Unseen Viewpoints, Articulations, Shapes and Objects for 3D Hand Pose Estimation under Hand-Object Interaction
To address these issues, we designed a public challenge (HANDS'19) to evaluate the abilities of current 3D hand pose estimators (HPEs) to interpolate and extrapolate the poses of a training set.

Predicting Sharp and Accurate Occlusion Boundaries in Monocular Depth Estimation Using Displacement Fields
Current methods for depth map prediction from monocular images tend to predict smooth, poorly localized contours for the occlusion boundaries in the input image.
General 3D Room Layout from a Single View by Render-and-Compare
In order to deal with occlusions between components of the layout, which is a problem ignored by previous works, we introduce an analysis-by-synthesis method to iteratively refine the 3D layout estimate.
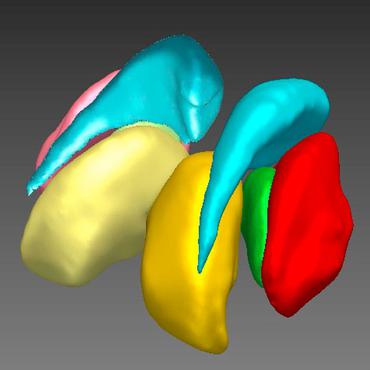
AssemblyNet: A large ensemble of CNNs for 3D Whole Brain MRI Segmentation
Finally, we showed the interest of using semi-supervised learning to improve the performance of our method.
Smart Hypothesis Generation for Efficient and Robust Room Layout Estimation
We propose a novel method to efficiently estimate the spatial layout of a room from a single monocular RGB image.
LU-Net: An Efficient Network for 3D LiDAR Point Cloud Semantic Segmentation Based on End-to-End-Learned 3D Features and U-Net
We propose LU-Net -- for LiDAR U-Net, a new method for the semantic segmentation of a 3D LiDAR point cloud.
CorNet: Generic 3D Corners for 6D Pose Estimation of New Objects without Retraining
We first learn to detect object corners of various shapes in images and also to predict their 3D poses, by using training images of a small set of objects.
On Object Symmetries and 6D Pose Estimation from Images
Objects with symmetries are common in our daily life and in industrial contexts, but are often ignored in the recent literature on 6D pose estimation from images.
Location Field Descriptors: Single Image 3D Model Retrieval in the Wild
We present Location Field Descriptors, a novel approach for single image 3D model retrieval in the wild.
GP2C: Geometric Projection Parameter Consensus for Joint 3D Pose and Focal Length Estimation in the Wild
We present a joint 3D pose and focal length estimation approach for object categories in the wild.
Sparse-to-Dense Hypercolumn Matching for Long-Term Visual Localization
Given a query image, we first match it against a database of registered reference images, using recent retrieval techniques.
HOnnotate: A method for 3D Annotation of Hand and Object Poses
This dataset is currently made of 77, 558 frames, 68 sequences, 10 persons, and 10 objects.

AssemblyNet: A Novel Deep Decision-Making Process for Whole Brain MRI Segmentation
Whole brain segmentation using deep learning (DL) is a very challenging task since the number of anatomical labels is very high compared to the number of available training images.
SharpNet: Fast and Accurate Recovery of Occluding Contours in Monocular Depth Estimation
We demonstrate our approach on the challenging NYUv2-Depth dataset, and show that our method outperforms the state-of-the-art along occluding contours, while performing on par with the best recent methods for the rest of the images.
 Ranked #51 on
Monocular Depth Estimation
on NYU-Depth V2
Ranked #51 on
Monocular Depth Estimation
on NYU-Depth V2
Casting Geometric Constraints in Semantic Segmentation as Semi-Supervised Learning
We propose a simple yet effective method to learn to segment new indoor scenes from video frames: State-of-the-art methods trained on one dataset, even as large as the SUNRGB-D dataset, can perform poorly when applied to images that are not part of the dataset, because of the dataset bias, a common phenomenon in computer vision.
Speed Invariant Time Surface for Learning to Detect Corner Points with Event-Based Cameras
We first introduce an efficient way to compute a time surface that is invariant to the speed of the objects.
Generalized Feedback Loop for Joint Hand-Object Pose Estimation
We show that we can correct the mistakes made by a Convolutional Neural Network trained to predict an estimate of the 3D pose by using a feedback loop.
S4-Net: Geometry-Consistent Semi-Supervised Semantic Segmentation
We show that it is possible to learn semantic segmentation from very limited amounts of manual annotations, by enforcing geometric 3D constraints between multiple views.

Improving Nighttime Retrieval-Based Localization
Outdoor visual localization is a crucial component to many computer vision systems.

HANDS18: Methods, Techniques and Applications for Hand Observation
The fourth instantiation of this workshop attracted significant interest from both academia and the industry.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation.
Domain Transfer for 3D Pose Estimation from Color Images without Manual Annotations
We introduce a novel learning method for 3D pose estimation from color images.
Geometry-Aware Network for Non-Rigid Shape Prediction from a Single View
We propose a method for predicting the 3D shape of a deformable surface from a single view.
Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation
We introduce a novel method for robust and accurate 3D object pose estimation from a single color image under large occlusions.
3D Pose Estimation and 3D Model Retrieval for Objects in the Wild
We propose a scalable, efficient and accurate approach to retrieve 3D models for objects in the wild.
Feature Mapping for Learning Fast and Accurate 3D Pose Inference from Synthetic Images
The ability of using synthetic images for training a Deep Network is extremely valuable as it is easy to create a virtually infinite training set made of such images, while capturing and annotating real images can be very cumbersome.
Learning to Find Good Correspondences
We develop a deep architecture to learn to find good correspondences for wide-baseline stereo.
HandSeg: An Automatically Labeled Dataset for Hand Segmentation from Depth Images
We propose an automatic method for generating high-quality annotations for depth-based hand segmentation, and introduce a large-scale hand segmentation dataset.

Going Further with Point Pair Features
Point Pair Features is a widely used method to detect 3D objects in point clouds, however they are prone to fail in presence of sensor noise and background clutter.
On Pre-Trained Image Features and Synthetic Images for Deep Learning
Deep Learning methods usually require huge amounts of training data to perform at their full potential, and often require expensive manual labeling.

ALCN: Meta-Learning for Contrast Normalization Applied to Robust 3D Pose Estimation
We therefore propose a novel illumination normalization method that lets us learn to detect objects and estimate their 3D pose under challenging illumination conditions from very few training samples.
DeepPrior++: Improving Fast and Accurate 3D Hand Pose Estimation
DeepPrior is a simple approach based on Deep Learning that predicts the joint 3D locations of a hand given a depth map.
 Ranked #10 on
Hand Pose Estimation
on MSRA Hands
Ranked #10 on
Hand Pose Estimation
on MSRA Hands
Learning to Align Semantic Segmentation and 2.5D Maps for Geolocalization
We present an efficient method for geolocalization in urban environments starting from a coarse estimate of the location provided by a GPS and using a simple untextured 2. 5D model of the surrounding buildings.
BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth
We introduce a novel method for 3D object detection and pose estimation from color images only.
 Ranked #19 on
6D Pose Estimation using RGB
on LineMOD
Ranked #19 on
6D Pose Estimation using RGB
on LineMOD
Monocular LSD-SLAM Integration within AR System
In this paper, we cover the process of integrating Large-Scale Direct Simultaneous Localization and Mapping (LSD-SLAM) algorithm into our existing AR stereo engine, developed for our modified "Augmented Reality Oculus Rift".

Training a Feedback Loop for Hand Pose Estimation
We propose an entirely data-driven approach to estimating the 3D pose of a hand given a depth image.
Fine Hand Segmentation using Convolutional Neural Networks
We propose a method for extracting very accurate masks of hands in egocentric views.
Hashmod: A Hashing Method for Scalable 3D Object Detection
We present a scalable method for detecting objects and estimating their 3D poses in RGB-D data.
Structured Prediction of 3D Human Pose with Deep Neural Networks
Most recent approaches to monocular 3D pose estimation rely on Deep Learning.
 Ranked #313 on
3D Human Pose Estimation
on Human3.6M
Ranked #313 on
3D Human Pose Estimation
on Human3.6M

Efficiently Creating 3D Training Data for Fine Hand Pose Estimation
While many recent hand pose estimation methods critically rely on a training set of labelled frames, the creation of such a dataset is a challenging task that has been overlooked so far.
LIFT: Learned Invariant Feature Transform
We introduce a novel Deep Network architecture that implements the full feature point handling pipeline, that is, detection, orientation estimation, and feature description.
An Efficient Minimal Solution for Multi-Camera Motion
We propose an efficient method for estimating the motion of a multi-camera rig from a minimal set of feature correspondences.
A Novel Representation of Parts for Accurate 3D Object Detection and Tracking in Monocular Images
We present a method that estimates in real-time and under challenging conditions the 3D pose of a known object.
Projection Onto the Manifold of Elongated Structures for Accurate Extraction
Detection of elongated structures in 2D images and 3D image stacks is a critical prerequisite in many applications and Machine Learning-based approaches have recently been shown to deliver superior performance.
Direct Prediction of 3D Body Poses from Motion Compensated Sequences
We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people.
Learning to Assign Orientations to Feature Points
We show how to train a Convolutional Neural Network to assign a canonical orientation to feature points given an image patch centered on the feature point.
Predicting people’s 3D poses from short sequences
We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people.
Ranked #314 on
3D Human Pose Estimation
on Human3.6M
Predicting People's 3D Poses from Short Sequences
We propose an efficient approach to exploiting motion information from consecutive frames of a video sequence to recover the 3D pose of people.
Global 6DOF Pose Estimation from Untextured 2D City Models
By contrast, our method returns an accurate, absolute camera pose in an absolute referential using simple 2D+height maps, which are broadly available, to refine a first estimate of the pose provided by the device's sensors.
Hands Deep in Deep Learning for Hand Pose Estimation
We introduce and evaluate several architectures for Convolutional Neural Networks to predict the 3D joint locations of a hand given a depth map.
Learning Descriptors for Object Recognition and 3D Pose Estimation
Detecting poorly textured objects and estimating their 3D pose reliably is still a very challenging problem.
On Rendering Synthetic Images for Training an Object Detector
We propose a novel approach to synthesizing images that are effective for training object detectors.
Flying Objects Detection from a Single Moving Camera
We propose an approach to detect flying objects such as UAVs and aircrafts when they occupy a small portion of the field of view, possibly moving against complex backgrounds, and are filmed by a camera that itself moves.

TILDE: A Temporally Invariant Learned DEtector
We introduce a learning-based approach to detect repeatable keypoints under drastic imaging changes of weather and lighting conditions to which state-of-the-art keypoint detectors are surprisingly sensitive.
Beyond KernelBoost
In this Technical Report we propose a set of improvements with respect to the KernelBoost classifier presented in [Becker et al., MICCAI 2013].
Multiscale Centerline Detection by Learning a Scale-Space Distance Transform
We propose a robust and accurate method to extract the centerlines and scale of tubular structures in 2D images and 3D volumes.
Robust 3D Tracking with Descriptor Fields
We introduce a method that can register challenging images from specular and poorly textured 3D environments, on which previous approaches fail.
Boosting Binary Keypoint Descriptors
Binary keypoint descriptors provide an efficient alternative to their floating-point competitors as they enable faster processing while requiring less memory.
Learning Separable Filters
Learning filters to produce sparse image representations in terms of overcomplete dictionaries has emerged as a powerful way to create image features for many different purposes.
Learning Image Descriptors with the Boosting-Trick
The main goal of local feature descriptors is to distinctively represent a salient image region while remaining invariant to viewpoint and illumination changes.

