Search Results for author:
Found 106 papers, 40 papers with code
Recurrent Image Annotation With Explicit Inter-Label Dependencies
Additionally, it provides a new perspecitve of looking at an unordered set of labels as equivalent to a collection of different permutations (sequences) of those labels, thus naturally aligning with the image annotation task.

IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
Intelligent vehicle systems require a deep understanding of the interplay between road conditions, surrounding entities, and the ego vehicle's driving behavior for safe and efficient navigation.
Towards Accurate Lip-to-Speech Synthesis in-the-Wild
In this paper, we introduce a novel approach to address the task of synthesizing speech from silent videos of any in-the-wild speaker solely based on lip movements.


Multiple Instance Learning for Glioma Diagnosis using Hematoxylin and Eosin Whole Slide Images: An Indian Cohort Study
It establishes new performance benchmarks in glioma subtype classification across multiple datasets, including a novel dataset focused on the Indian demographic (IPD- Brain), providing a valuable resource for existing research.
Overcoming Label Noise for Source-free Unsupervised Video Domain Adaptation
We use the source pre-trained model to generate pseudo-labels for the target domain samples, which are inevitably noisy.

Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge.
United We Stand, Divided We Fall: UnityGraph for Unsupervised Procedure Learning from Videos
Given multiple videos of the same task, procedure learning addresses identifying the key-steps and determining their order to perform the task.
Explaining Deep Face Algorithms through Visualization: A Survey
Although current deep models for face tasks surpass human performance on some benchmarks, we do not understand how they work.
Understanding Video Scenes through Text: Insights from Text-based Video Question Answering
Researchers have extensively studied the field of vision and language, discovering that both visual and textual content is crucial for understanding scenes effectively.

Towards Real-Time Analysis of Broadcast Badminton Videos
In this work, we propose an end-to-end framework for player movement analysis for badminton matches on live broadcast match videos.
Reading Between the Lanes: Text VideoQA on the Road
Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness.
CueCAn: Cue Driven Contextual Attention For Identifying Missing Traffic Signs on Unconstrained Roads
MTSVD is challenging compared to the previous works in two aspects i) The traffic signs are generally not present in the vicinity of their cues, ii) The traffic signs cues are diverse and unique.

A Fine-Grained Vehicle Detection (FGVD) Dataset for Unconstrained Roads
Along with providing baseline results for existing object detectors on FGVD Dataset, we also present the results of a combination of an existing detector and the recent Hierarchical Residual Network (HRN) classifier for the FGVD task.
Towards Robust Handwritten Text Recognition with On-the-fly User Participation
The service providers encourage the users who provide data where the OCR model fails by rewarding them based on data complexity, readability, and available budget.
 Handwritten Text Recognition
Handwritten Text Recognition
 Optical Character Recognition (OCR)
Optical Character Recognition (OCR)
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts.
Information Retrieval from the Digitized Books
Extracting the relevant information out of a large number of documents is a challenging and tedious task.


Watching the News: Towards VideoQA Models that can Read
We demonstrate the limitations of current Scene Text VQA and VideoQA methods and propose ways to incorporate scene text information into VideoQA methods.
Unsupervised Audio-Visual Lecture Segmentation
We formulate lecture segmentation as an unsupervised task that leverages visual, textual, and OCR cues from the lecture, while clip representations are fine-tuned on a pretext self-supervised task of matching the narration with the temporally aligned visual content.
INR-V: A Continuous Representation Space for Video-based Generative Tasks
In this work, we evaluate the space learned by INR-V on diverse generative tasks such as video interpolation, novel video generation, video inversion, and video inpainting against the existing baselines.
 Ranked #1 on
Video Inpainting
on How2Sign
Ranked #1 on
Video Inpainting
on How2Sign


IDD-3D: Indian Driving Dataset for 3D Unstructured Road Scenes
Autonomous driving and assistance systems rely on annotated data from traffic and road scenarios to model and learn the various object relations in complex real-world scenarios.


Grounded Video Situation Recognition
Recently, Video Situation Recognition (VidSitu) is framed as a task for structured prediction of multiple events, their relationships, and actions and various verb-role pairs attached to descriptive entities.
Lip-to-Speech Synthesis for Arbitrary Speakers in the Wild
With the help of multiple powerful discriminators that guide the training process, our generator learns to synthesize speech sequences in any voice for the lip movements of any person.

FaceOff: A Video-to-Video Face Swapping System
To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video.

Extreme-scale Talking-Face Video Upsampling with Audio-Visual Priors
We show that when we process this $8\times8$ video with the right set of audio and image priors, we can obtain a full-length, $256\times256$ video.


TRoVE: Transforming Road Scene Datasets into Photorealistic Virtual Environments
We show that using annotations and visual cues from existing datasets, we can facilitate automated multi-modal data generation, mimicking real scene properties with high-fidelity, along with mechanisms to diversify samples in a physically meaningful way.

My View is the Best View: Procedure Learning from Egocentric Videos
Instead, we propose to use the signal provided by the temporal correspondences between key-steps across videos.
Detecting, Tracking and Counting Motorcycle Rider Traffic Violations on Unconstrained Roads
In many Asian countries with unconstrained road traffic conditions, driving violations such as not wearing helmets and triple-riding are a significant source of fatalities involving motorcycles.
Classroom Slide Narration System
With this information, we build a Classroom Slide Narration System (CSNS) to help VI students understand the slide content.
Automatic Quantification and Visualization of Street Trees
We obtain TCDCA of 96. 77% on the test videos, with a remarkable improvement of 22. 58% over baseline, and demonstrate that our counting module's performance is close to human level.
Transfer Learning for Scene Text Recognition in Indian Languages
WRRs improve over the baselines by 8%, 4%, 5%, and 3% on the MLT-19 Hindi and Bangla datasets and the Gujarati and Tamil datasets.

Towards Boosting the Accuracy of Non-Latin Scene Text Recognition
Several controlled experiments are performed on English, by varying the number of (i) fonts to create the synthetic data and (ii) created word images.
To miss-attend is to misalign! Residual Self-Attentive Feature Alignment for Adapting Object Detectors
Qualitative results demonstrate the ability of ILLUME to attend important object instances required for alignment.


ICDAR 2021 Competition on Document VisualQuestion Answering
In this report we present results of the ICDAR 2021 edition of the Document Visual Question Challenges.

Multi-Domain Incremental Learning for Semantic Segmentation
Recent efforts in multi-domain learning for semantic segmentation attempt to learn multiple geographical datasets in a universal, joint model.


Intelligent Video Editing: Incorporating Modern Talking Face Generation Algorithms in a Video Editor
Our evaluations show a clear improvement in the efficiency of using human editors and an improved video generation quality.

Ego4D: Around the World in 3,000 Hours of Egocentric Video
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite.
Evaluating Computer Vision Techniques for Urban Mobility on Large-Scale, Unconstrained Roads
Conventional approaches for addressing road safety rely on manual interventions or immobile CCTV infrastructure.
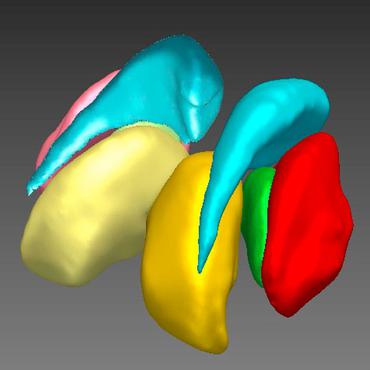
DeepPocket: Ligand Binding Site Detection and Segmentation using 3D Convolutional Neural Networks
A structure-based drug design pipeline involves the development of potential drug molecules or ligands that form stable complexes with a given receptor at its binding site.
Efficient and Generic Interactive Segmentation Framework to Correct Mispredictions during Clinical Evaluation of Medical Images
We report a time saving of 2. 8, 3. 0, 1. 9, 4. 4, and 8. 6 fold compared to other interactive segmentation techniques.
ICDAR2019 Competition on Scanned Receipt OCR and Information Extraction
In this competition, we set up three tasks, namely, Scanned Receipt Text Localisation (Task 1), Scanned Receipt OCR (Task 2) and Key Information Extraction from Scanned Receipts (Task 3).
Key Information Extraction
Optical Character Recognition (OCR)
+1
Context Aware Group Activity Recognition
Existing approaches decompose this task into feature learning and relational reasoning.
Few Shot Learning With No Labels
Few-shot learners aim to recognize new categories given only a small number of training samples.
Visual Speech Enhancement Without A Real Visual Stream
In this work, we re-think the task of speech enhancement in unconstrained real-world environments.
 Ranked #1 on
Speech Denoising
on LRS3+VGGSound
Ranked #1 on
Speech Denoising
on LRS3+VGGSound

Improving Word Recognition using Multiple Hypotheses and Deep Embeddings
We propose a novel scheme for improving the word recognition accuracy using word image embeddings.
Table Structure Recognition using Top-Down and Bottom-Up Cues
We present an approach for table structure recognition that combines cell detection and interaction modules to localize the cells and predict their row and column associations with other detected cells.
 Ranked #9 on
Table Recognition
on PubTabNet
Ranked #9 on
Table Recognition
on PubTabNet
Graphical Object Detection in Document Images
Graphical elements: particularly tables and figures contain a visual summary of the most valuable information contained in a document.
CDeC-Net: Composite Deformable Cascade Network for Table Detection in Document Images
Localizing page elements/objects such as tables, figures, equations, etc.
 Ranked #1 on
Table Detection
on ICDAR2013
Ranked #1 on
Table Detection
on ICDAR2013


A Lip Sync Expert Is All You Need for Speech to Lip Generation In The Wild
However, they fail to accurately morph the lip movements of arbitrary identities in dynamic, unconstrained talking face videos, resulting in significant parts of the video being out-of-sync with the new audio.
 Ranked #1 on
Unconstrained Lip-synchronization
on LRS3
(using extra training data)
Ranked #1 on
Unconstrained Lip-synchronization
on LRS3
(using extra training data)
Document Visual Question Answering Challenge 2020
For the task 1 a new dataset is introduced comprising 50, 000 questions-answer(s) pairs defined over 12, 767 document images.
Revisiting Low Resource Status of Indian Languages in Machine Translation
Through this paper, we provide and analyse an automated framework to obtain such a corpus for Indian language neural machine translation (NMT) systems.

Textual Description for Mathematical Equations
Reading of mathematical expression or equation in the document images is very challenging due to the large variability of mathematical symbols and expressions.
IIIT-AR-13K: A New Dataset for Graphical Object Detection in Documents
This dataset, IIIT-AR-13k, is created by manually annotating the bounding boxes of graphical or page objects in publicly available annual reports.
Weakly Supervised Instance Segmentation by Learning Annotation Consistent Instances
Recent approaches for weakly supervised instance segmentations depend on two components: (i) a pseudo label generation model that provides instances which are consistent with a given annotation; and (ii) an instance segmentation model, which is trained in a supervised manner using the pseudo labels as ground-truth.
 Ranked #4 on
Image-level Supervised Instance Segmentation
on PASCAL VOC 2012 val
(using extra training data)
Ranked #4 on
Image-level Supervised Instance Segmentation
on PASCAL VOC 2012 val
(using extra training data)
Image-level Supervised Instance Segmentation
Pseudo Label
+3
A Multilingual Parallel Corpora Collection Effort for Indian Languages
We present sentence aligned parallel corpora across 10 Indian Languages - Hindi, Telugu, Tamil, Malayalam, Gujarati, Urdu, Bengali, Oriya, Marathi, Punjabi, and English - many of which are categorized as low resource.
DocVQA: A Dataset for VQA on Document Images
The dataset consists of 50, 000 questions defined on 12, 000+ document images.
 Ranked #1 on
Visual Question Answering (VQA)
on DocVQA val
Ranked #1 on
Visual Question Answering (VQA)
on DocVQA val

Fused Text Recogniser and Deep Embeddings Improve Word Recognition and Retrieval
Recognition and retrieval of textual content from the large document collections have been a powerful use case for the document image analysis community.
RoadText-1K: Text Detection & Recognition Dataset for Driving Videos
State of the art methods for text detection, recognition and tracking are evaluated on the new dataset and the results signify the challenges in unconstrained driving videos compared to existing datasets.
Learning Individual Speaking Styles for Accurate Lip to Speech Synthesis
In this work, we explore the task of lip to speech synthesis, i. e., learning to generate natural speech given only the lip movements of a speaker.
 Ranked #1 on
Lip Reading
on LRW
Ranked #1 on
Lip Reading
on LRW

IndicSpeech: Text-to-Speech Corpus for Indian Languages
We believe that one of the major reasons for this is the lack of large, publicly available text-to-speech corpora in these languages that are suitable for training neural text-to-speech systems.
Towards Automatic Face-to-Face Translation
As today's digital communication becomes increasingly visual, we argue that there is a need for systems that can automatically translate a video of a person speaking in language A into a target language B with realistic lip synchronization.
 Ranked #1 on
Talking Face Generation
on LRW
(using extra training data)
Ranked #1 on
Talking Face Generation
on LRW
(using extra training data)
ICDAR 2019 Robust Reading Challenge on Reading Chinese Text on Signboard
21 teams submit results for Task 1, 23 teams submit results for Task 2, 24 teams submit results for Task 3, and 13 teams submit results for Task 4.
A Deep Learning Approach for Robust Corridor Following
For an autonomous corridor following task where the environment is continuously changing, several forms of environmental noise prevent an automated feature extraction procedure from performing reliably.
CVIT's submissions to WAT-2019
This paper describes the Neural Machine Translation systems used by IIIT Hyderabad (CVIT-MT) for the translation tasks part of WAT-2019.
A Baseline Neural Machine Translation System for Indian Languages
We present a simple, yet effective, Neural Machine Translation system for Indian languages.
ICDAR 2019 Competition on Scene Text Visual Question Answering
ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image.
Scene Text Visual Question Answering
Current visual question answering datasets do not consider the rich semantic information conveyed by text within an image.
A Cost Efficient Approach to Correct OCR Errors in Large Document Collections
Word error rate of an ocr is often higher than its character error rate.

CVIT-MT Systems for WAT-2018
This document describes the machine translation system used in the submissions of IIIT-Hyderabad CVIT-MT for the WAT-2018 English-Hindi translation task.
Self-Supervised Visual Representations for Cross-Modal Retrieval
Cross-modal retrieval methods have been significantly improved in last years with the use of deep neural networks and large-scale annotated datasets such as ImageNet and Places.

Low-Cost Transfer Learning of Face Tasks
Do we know what the different filters of a face network represent?

Universal Semi-Supervised Semantic Segmentation
In recent years, the need for semantic segmentation has arisen across several different applications and environments.
 Ranked #27 on
Semantic Segmentation
on DensePASS
(using extra training data)
Ranked #27 on
Semantic Segmentation
on DensePASS
(using extra training data)

City-Scale Road Audit System using Deep Learning
Road networks in cities are massive and is a critical component of mobility.
IDD: A Dataset for Exploring Problems of Autonomous Navigation in Unconstrained Environments
It also reflects label distributions of road scenes significantly different from existing datasets, with most classes displaying greater within-class diversity.
Dissimilarity Coefficient based Weakly Supervised Object Detection
This allows us to use a state of the art discrete generative model that can provide annotation consistent samples from the conditional distribution.

Improved Visual Relocalization by Discovering Anchor Points
Our method improves the median error in indoor as well as outdoor localization datasets compared to the previous best deep learning model known as PoseNet (with geometric re-projection loss) using the same feature extractor.
Class2Str: End to End Latent Hierarchy Learning
We propose an alternate architecture to the classifier network called the Latent Hierarchy (LH) Classifier and an end to end learned Class2Str mapping which discovers a latent hierarchy of the classes.

Connecting Visual Experiences using Max-flow Network with Application to Visual Localization
This problem is solved by finding the maximum flow in a directed graph flow-network, whose vertices represent the matches between frames in the test and reference sequences.
Learning Human Poses from Actions
In order to avoid the high cost of full supervision, we propose to use a diverse data set, which consists of two types of annotations: (i) a small number of images are labeled using the expensive ground-truth pose; and (ii) other images are labeled using the inexpensive action label.
TextTopicNet - Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
We show that adequate visual features can be learned efficiently by training a CNN to predict the semantic textual context in which a particular image is more probable to appear as an illustration.
Efficient Semantic Segmentation using Gradual Grouping
We study the effectiveness of these techniques on a real-time semantic segmentation architecture like ERFNet for improving run time by over 5X.

Unsupervised Learning of Face Representations
Although faces extracted from videos have a lower spatial resolution than those which are available as part of standard supervised face datasets such as LFW and CASIA-WebFace, the former represent a much more realistic setting, e. g. in surveillance scenarios where most of the faces detected are very small.
HWNet v2: An Efficient Word Image Representation for Handwritten Documents
We present a framework for learning an efficient holistic representation for handwritten word images.
SmartTennisTV: Automatic indexing of tennis videos
In this paper, we demonstrate a score based indexing approach for tennis videos.
Towards Structured Analysis of Broadcast Badminton Videos
Sports video data is recorded for nearly every major tournament but remains archived and inaccessible to large scale data mining and analytics.
An EEG-based Image Annotation System
The success of deep learning in computer vision has greatly increased the need for annotated image datasets.

Unconstrained Scene Text and Video Text Recognition for Arabic Script
For scripts like Arabic, a major challenge in developing robust recognizers is the lack of large quantity of annotated data.
Pose-Aware Person Recognition
Person recognition methods that use multiple body regions have shown significant improvements over traditional face-based recognition.
Self-supervised learning of visual features through embedding images into text topic spaces
End-to-end training from scratch of current deep architectures for new computer vision problems would require Imagenet-scale datasets, and this is not always possible.
Automated Top View Registration of Broadcast Football Videos
The proposed method is fully automatic in contrast to the current state of the art which requires manual initialization of point correspondences between the image and the static model.
Align Me: A framework to generate Parallel Corpus Using OCRs and Bilingual Dictionaries
Multilingual language processing tasks like statistical machine translation and cross language information retrieval rely mainly on availability of accurate parallel corpora.
Generating Synthetic Data for Text Recognition
Generating synthetic images is an art which emulates the natural process of image generation in a closest possible manner.


First Person Action Recognition Using Deep Learned Descriptors
It can also be trained from relatively small number of labeled egocentric videos that are available.


Matching Handwritten Document Images
We address the problem of predicting similarity between a pair of handwritten document images written by different individuals.
Efficient Optimization for Rank-based Loss Functions
We provide a complete characterization of the loss functions that are amenable to our algorithm, and show that it includes both AP and NDCG based loss functions.
Trajectory Aligned Features For First Person Action Recognition
Objects present in the scene and hand gestures of the wearer are the most important cues for first person action recognition but are difficult to segment and recognize in an egocentric video.
Enhancing Energy Minimization Framework for Scene Text Recognition with Top-Down Cues
We build a conditional random field model on these detections to jointly model the strength of the detections and the interactions between them.
Visual Phrases for Exemplar Face Detection
Contrary to traditional approaches that model face variations from a large and diverse set of training examples, exemplar-based approaches use a collection of discriminatively trained exemplars for detection.

Multi-Label Cross-Modal Retrieval
In this work, we address the problem of cross-modal retrieval in presence of multi-label annotations.
TennisVid2Text: Fine-grained Descriptions for Domain Specific Videos
In this work, we attempt to describe videos from a specific domain - broadcast videos of lawn tennis matches.
Efficient Optimization for Average Precision SVM
The accuracy of information retrieval systems is often measured using average precision (AP).

Optimizing Average Precision using Weakly Supervised Data
The performance of binary classification tasks, such as action classification and object detection, is often measured in terms of the average precision (AP).
Parsing World's Skylines using Shape-Constrained MRFs
We propose an approach for segmenting the individual buildings in typical skyline images.
Relative Parts: Distinctive Parts for Learning Relative Attributes
The notion of relative attributes as introduced by Parikh and Grauman (ICCV, 2011) provides an appealing way of comparing two images based on their visual properties (or attributes) such as "smiling" for face images, "naturalness" for outdoor images, etc.
Blocks That Shout: Distinctive Parts for Scene Classification
The automatic discovery of distinctive parts for an object or scene class is challenging since it requires simultaneously to learn the part appearance and also to identify the part occurrences in images.

Learning Multiple Non-linear Sub-spaces Using K-RBMs
In this paper, we describe a feature learning scheme for natural images.

Scene Text Recognition using Higher Order Language Priors
The problem of recognizing text in images taken in the wild has gained significant attention from the computer vision community in recent years.
